
We spin up an Azure ND MI300X v5 node via CloudRift.ai, keep everything apt‑managed, and hit ~49–51 tok/s on GLM‑4.6—with the flags, caches, and gotchas (including AITer’s power‑of‑2 experts).
Node: 8× MI300X (192 GB HBM3 each, ~5.3 TB/s), dual Xeon, 8× NVMe RAID‑0 (≈30 TB).
OS/Stack: Ubuntu 24.04.3 + 6.14 HWE / azure + ROCm 7.0.2—no source builds.
Throughput tip: HF_HUB_ENABLE_HF_TRANSFER=0 + HF_XET_HIGH_PERFORMANCE=1 doubled model pulls to >20 Gb/s
GLM‑4.6 BF16: AITer fused‑MoE blocked by 160 experts (non power‑of‑2); ~49–51 tok/s single concurrency out-of-the-box
What’s next: FP8 + GLM‑4.6‑Air (power‑of‑2 experts) to unlock fused‑MoE paths. Ring-1T? ComfyUI Parallel Flows?
Why AMD Instinct MI300X Now?
AMD’s ROCm 7.x era is a real inflection point: setup on modern Debian based distributions is finally “Day-0 simple” while the hardware’s HBM footprint and fabric bandwidth unlock private inference at scale. At the low end, RDNA‑based parts (Ryzen AI/Strix family, RX 7900 XTX) give small teams a credible, low‑concurrency path; at the high end, an 8× MI300X node like this one delivers 5.3 TB/s per‑GPU memory bandwidth and 1.5 TB of pooled HBM for running ~1 TB models with room left for KV cache. This is the line where “private cloud” moves from a slide to a system.
CloudRift.ai (and why we used them – and why we’d return)
CloudRift.ai is a NVIDIA‑focused provider that also has some AMD capability. Dmitry Trifonov (founder & CEO) gave us time on this AMD box specifically to validate the ROCm 7 day‑0 path on vLLM without building from source. That combination—NV fleet depth plus a hard‑to‑find MI300X node—is why we chose them for this piece. CloudRift.ai provided access to the MI300X node used for this testing; all configurations, observations, and benchmarks are our own.
What helped us move fast on MI300X:
- Day-0 image that matched our stack: Ubuntu 24.04.3 + 6.14 HWE with ROCm 7.0.2 already in place (no source build); containers for vLLM/SGLang/OpenWebUI/ComfyUI/Prometheus ready to pull. This alone shaved hours of OS/driver yak shaving.
- The “right” node for very‑large models: Azure ND MI300X v5 (8× MI300X, 192 GB HBM3 each ~5.3 TB/s), dual Xeon, and 8× NVMe RAID‑0 (~30 TB)—exactly what you want for 0.5–1.0 TB checkpoints with meaningful KV headroom.
- Pre‑wired caches & apt‑managed tooling: HF cache, Docker cache, uv via apt—so we could bind volumes, persist JIT artifacts, and keep vLLM cold‑start costs down.
- The AMD “model shelf” (handful of FP8 giants pre‑staged) to cut first‑day download time. We might add some matching pinned ROCm 7.0.2 / vLLM 0.11.x images preconfigured with the correct AITer tunables for different model classes just to make it even easier to jump right in.
- A small env‑tweak that paid off big: On this node, turning off HF_HUB_ENABLE_HF_TRANSFER and setting HF_XET_HIGH_PERFORMANCE=1 pushed model pulls past 20 Gb/s—handy when you’re staging multi‑hundred‑GB repos.
Why that matters: when you’re billed by the hour, time‑to‑first‑token beats everything. CloudRift’s curated image + caches let us spend time on models, flags, and numbers—not on package archaeology.
Our Testbed: CloudRift on Azure ND MI300X v5
The hardware behind this instance is impressive.
- GPUs: 8x AMD Instinct MI300X GPUs.
- 192 GB HBM3 per GPU, ~5.3 TB/s memory bandwidth
- CPU: 2x 4th-Gen Intel Xeon Scalable processors, totaling 96 physical cores.
- 128 GB/s per‑link Infinity Fabric; 896 GB/s fully interconnected in an 8‑GPU UBB node
- Storage: 8 NVMe 3.5 TB drives arranged in a RAID-0 array
These numbers matter: they let you run big models in full precision and keep a viable KV cache.
Day‑0 Experience (No Building From Source)
One of the first things we noticed was the modern software stack CloudRift.ai had running on this instance. It was running the current Ubuntu 24.04.3 distribution with the 6.14 HWE kernel, which is the most advanced combination of Linux kernel and Operating system that is fully supported by the AMD ROCm 7 series with the AMD ROCm 7.0.2 software stack at the time of publication.
It is worth noting, the current guidance from Microsoft (dated 4/24/25) indicates Ubuntu 22.04 + Kernel 5.15 + ROCm 6.22 should be used. Even the current and related AzureHPC Marketplace N-series documentation (dated 10/16/25) points only to ROCm 7.0.1 sources for other AMD targets. This underscores the value of a provider that tracks the moving target. Immediately this saves time, often hours, that might otherwise be spent upgrading the platform and the driver stack to the very latest kit.
Caches and Containers
Beyond the default operating system and driver-ready hardware, the software layer on this CloudRift.ai instance came with a handful of other convenient features.
Containers: ROCm-tuned vLLM and SGLang images from AMD, OpenWebUI, ComfyUI, Prometheus – ready to bind caches and go.
Caches pre-wired: HF Cache, uv, and Docker cached to a large NVMe mount with envs preset
uv available via apt: drop in a uv.lock and recreate Python envs deterministically, in keeping with a pure apt-managed posture.
Throughput & Downloads (HF knobs that actually helped)
8 NVMe drives providing 30 TB of space in a RAID-0 configuration. One observation we made is that the HF_HUB_ENABLE_HF_TRANSFER=1 flag we use to improve performance pulling models over a 10Gbps network into our HF_HOME was actually holding back throughput. In the CloudRift.ai node, once we set HF_HUB_ENABLE_HF_TRANSFER=0 and HF_XET_HIGH_PERFORMANCE=1 the speeds jumped from 8-10 Gb/s and more than doubled to over 20 Gb/s. (uv add huggingface_hub[cli] hf_xet)
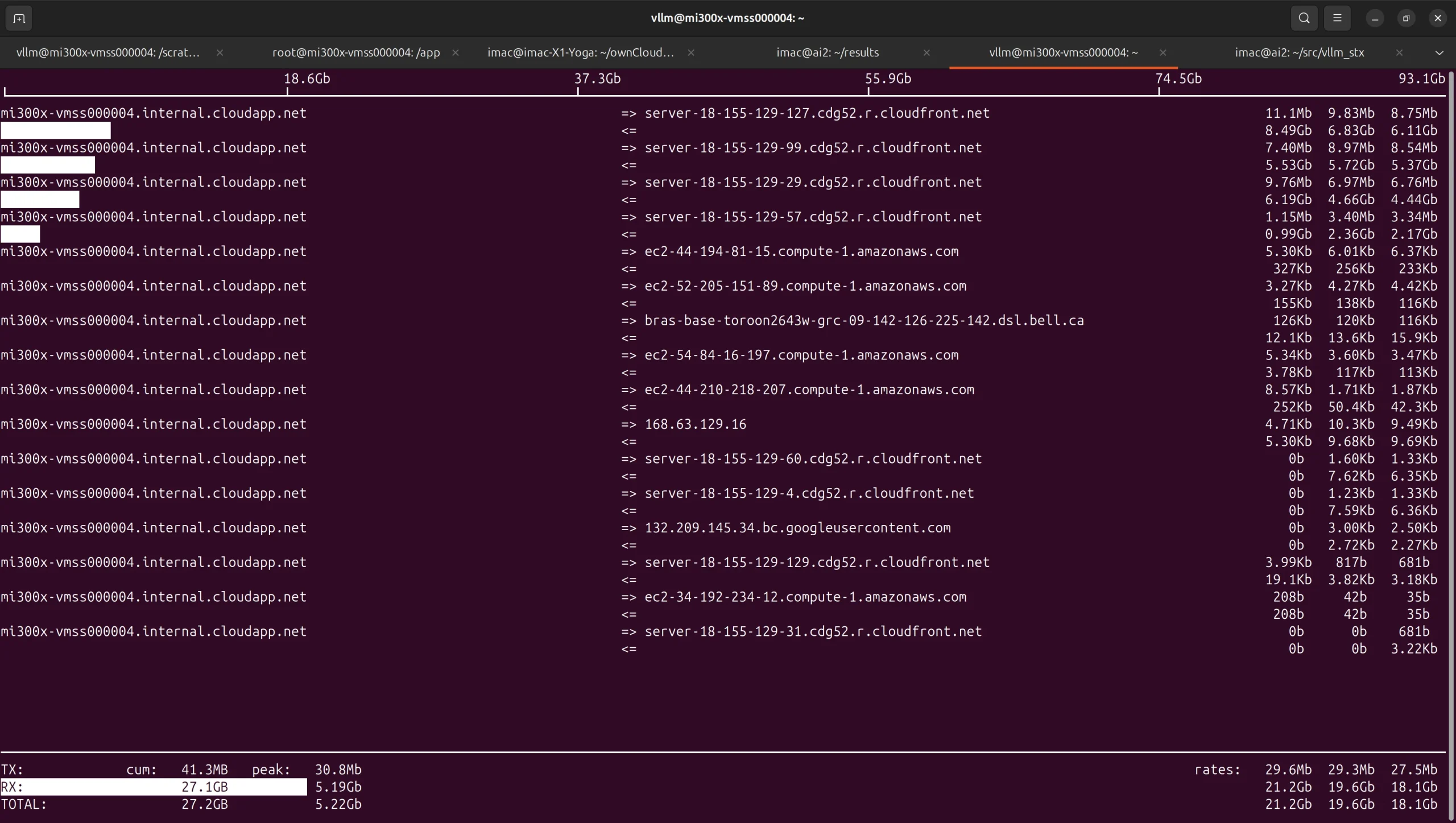
Hugging Face Pull at >20 Gb/s
We downloaded a number of interesting and varied MoE model architectures, and if we find the cycles, hope to showcase a model sweep and performance gains with recent changes to ROCm7 AITer and vLLM.
$ hf cache scan REPO ID REPO TYPE SIZE ON DISK NB FILES LAST_ACCESSED LAST_MODIFIED REFS LOCAL PATH --------------------------------------- --------- ------------ -------- ------------- ------------- ---- ----------------------------------------------------------------------------- Comfy-Org/Wan_2.2_ComfyUI_Repackaged model 677.1G 42 2 days ago 2 days ago main /root/.cache/huggingface/hub/models--Comfy-Org--Wan_2.2_ComfyUI_Repackaged Comfy-Org/stable-diffusion-3.5-fp8 model 48.0G 11 2 days ago 2 days ago main /root/.cache/huggingface/hub/models--Comfy-Org--stable-diffusion-3.5-fp8 Qwen/Qwen-Image-Edit-2509 model 57.7G 32 1 week ago 1 week ago main /root/.cache/huggingface/hub/models--Qwen--Qwen-Image-Edit-2509 Qwen/Qwen1.5-MoE-A2.7B-Chat model 28.6G 19 11 hours ago 11 hours ago main /root/.cache/huggingface/hub/models--Qwen--Qwen1.5-MoE-A2.7B-Chat Qwen/Qwen2.5-VL-72B-Instruct model 146.8G 50 1 week ago 1 week ago main /root/.cache/huggingface/hub/models--Qwen--Qwen2.5-VL-72B-Instruct Qwen/Qwen3-0.6B model 1.5G 10 1 week ago 1 week ago main /root/.cache/huggingface/hub/models--Qwen--Qwen3-0.6B Qwen/Qwen3-235B-A22B-Instruct-2507-FP8 model 236.4G 34 1 week ago 1 week ago main /root/.cache/huggingface/hub/models--Qwen--Qwen3-235B-A22B-Instruct-2507-FP8 Qwen/Qwen3-235B-A22B-Thinking-2507-FP8 model 236.4G 34 2 days ago 2 days ago main /root/.cache/huggingface/hub/models--Qwen--Qwen3-235B-A22B-Thinking-2507-FP8 Qwen/Qwen3-30B-A3B-FP8 model 32.5G 17 1 week ago 1 week ago main /root/.cache/huggingface/hub/models--Qwen--Qwen3-30B-A3B-FP8 Qwen/Qwen3-Coder-480B-A35B-Instruct model 960.3G 253 1 week ago 1 week ago main /root/.cache/huggingface/hub/models--Qwen--Qwen3-Coder-480B-A35B-Instruct Qwen/Qwen3-Coder-480B-A35B-Instruct-FP8 model 482.2G 61 1 week ago 1 week ago main /root/.cache/huggingface/hub/models--Qwen--Qwen3-Coder-480B-A35B-Instruct-FP8 Qwen/Qwen3-Next-80B-A3B-Instruct model 162.7G 51 1 week ago 1 week ago main /root/.cache/huggingface/hub/models--Qwen--Qwen3-Next-80B-A3B-Instruct Qwen/Qwen3-Next-80B-A3B-Instruct-FP8 model 82.1G 18 1 week ago 1 week ago main /root/.cache/huggingface/hub/models--Qwen--Qwen3-Next-80B-A3B-Instruct-FP8 Qwen/Qwen3-Next-80B-A3B-Thinking-FP8 model 82.1G 18 1 week ago 1 week ago main /root/.cache/huggingface/hub/models--Qwen--Qwen3-Next-80B-A3B-Thinking-FP8 Qwen/Qwen3-VL-235B-A22B-Instruct-FP8 model 237.6G 36 2 days ago 2 days ago main /root/.cache/huggingface/hub/models--Qwen--Qwen3-VL-235B-A22B-Instruct-FP8 Qwen/Qwen3-VL-235B-A22B-Thinking model 471.4G 108 1 week ago 1 week ago main /root/.cache/huggingface/hub/models--Qwen--Qwen3-VL-235B-A22B-Thinking RedHatAI/gemma-3-27b-it-FP8-dynamic model 29.3G 21 1 week ago 1 week ago main /root/.cache/huggingface/hub/models--RedHatAI--gemma-3-27b-it-FP8-dynamic allenai/OLMoE-1B-7B-0125 model 27.7G 15 8 hours ago 8 hours ago main /root/.cache/huggingface/hub/models--allenai--OLMoE-1B-7B-0125 amd/Llama-3.1-405B-Instruct-FP8-KV model 410.1G 97 1 week ago 1 week ago main /root/.cache/huggingface/hub/models--amd--Llama-3.1-405B-Instruct-FP8-KV amd/Llama-3.1-70B-Instruct-FP8-KV model 72.7G 26 1 week ago 1 week ago main /root/.cache/huggingface/hub/models--amd--Llama-3.1-70B-Instruct-FP8-KV amd/Llama-3.3-70B-Instruct-FP8-KV model 72.7G 26 1 week ago 1 week ago main /root/.cache/huggingface/hub/models--amd--Llama-3.3-70B-Instruct-FP8-KV amd/Mixtral-8x22B-Instruct-v0.1-FP8-KV model 141.0G 38 1 week ago 1 week ago main /root/.cache/huggingface/hub/models--amd--Mixtral-8x22B-Instruct-v0.1-FP8-KV amd/Mixtral-8x7B-Instruct-v0.1-FP8-KV model 50.4G 20 11 hours ago 11 hours ago main /root/.cache/huggingface/hub/models--amd--Mixtral-8x7B-Instruct-v0.1-FP8-KV deepseek-ai/DeepSeek-R1-0528 model 688.6G 174 1 week ago 1 week ago main /root/.cache/huggingface/hub/models--deepseek-ai--DeepSeek-R1-0528 deepseek-ai/DeepSeek-V3.1-Terminus model 688.6G 181 2 days ago 2 days ago main /root/.cache/huggingface/hub/models--deepseek-ai--DeepSeek-V3.1-Terminus ibm-granite/granite-4.0-h-small model 64.4G 26 1 week ago 1 week ago main /root/.cache/huggingface/hub/models--ibm-granite--granite-4.0-h-small ibm-granite/granite-docling-258M model 529.9M 17 1 week ago 1 week ago main /root/.cache/huggingface/hub/models--ibm-granite--granite-docling-258M mistralai/Mixtral-8x22B-Instruct-v0.1 model 281.3G 68 8 hours ago 8 hours ago main /root/.cache/huggingface/hub/models--mistralai--Mixtral-8x22B-Instruct-v0.1 mistralai/Mixtral-8x7B-Instruct-v0.1 model 190.5G 36 11 hours ago 11 hours ago main /root/.cache/huggingface/hub/models--mistralai--Mixtral-8x7B-Instruct-v0.1 moonshotai/Kimi-K2-Instruct-0905 model 1.0T 80 2 days ago 2 days ago main /root/.cache/huggingface/hub/models--moonshotai--Kimi-K2-Instruct-0905 openai/gpt-oss-120b model 130.5G 27 1 week ago 1 week ago main /root/.cache/huggingface/hub/models--openai--gpt-oss-120b unsloth/GLM-4.6-GGUF model 389.8G 8 6 days ago 6 days ago main /root/.cache/huggingface/hub/models--unsloth--GLM-4.6-GGUF unsloth/gpt-oss-120b-BF16 model 233.7G 82 6 days ago 6 days ago main /root/.cache/huggingface/hub/models--unsloth--gpt-oss-120b-BF16 zai-org/GLM-4.5 model 716.7G 101 2 days ago 2 days ago main /root/.cache/huggingface/hub/models--zai-org--GLM-4.5 zai-org/GLM-4.5-Air-FP8 model 112.6G 55 2 days ago 2 days ago main /root/.cache/huggingface/hub/models--zai-org--GLM-4.5-Air-FP8 zai-org/GLM-4.5-FP8 model 361.3G 101 2 days ago 2 days ago main /root/.cache/huggingface/hub/models--zai-org--GLM-4.5-FP8 zai-org/GLM-4.6 model 713.6G 101 2 days ago 2 days ago main /root/.cache/huggingface/hub/models--zai-org--GLM-4.6 zai-org/GLM-4.6-FP8 model 354.9G 100 2 days ago 2 days ago main /root/.cache/huggingface/hub/models--zai-org--GLM-4.6-FP8 Done in 0.1s. Scanned 38 repo(s) for a total of 10.7T.
Cache Quirks and Build Sources (how we avoided 50-second cold starts)
We added some directories to store the runtime outputs from our vLLM containers various JIT compilers. Matching environment variables set inside the container, the basic set includes PYTORCH_TUNABLEOP_FILENAME, JIT_WORKSPACE_DIR, AITER_JIT_DIR, HF_HOME and VLLM_CACHE_ROOT. These ensure all the just-in-time paged attention builds, kernel operators, and other cached items are not lost between container restarts and cuts down on warm-up time and cold starts if you are iterating on the same build. AMD ships pytorch tunable ops pre-tuned shapes inside their builds. If you are using AMD prebuilt images, or one based on the tuning build base image, you will already some of these benefits baked in.
We also added some additional AMD nightly vLLM builds to the docker library, as these often take advantage of cherry picked PRs against the next stable vLLM release, and often merge in specific ROCm and AITer fixes queued for future vLLM releases once they meet a broader set of vLLM requirements. Just building against the vLLM upstream tree with nightly pytorch wheels works, but may not match in performance.
Qwen Image Edit 2509
The new Qwen Image Edit arrived September 25th. This new Qwen Image Edit 2509 release introduced the ability to input up to three images of people, places and things and do almost anything with them. It is a big jump from the last release, and we could not resist testing how it performed out of the box on this CloudRift node. To do this we used a simple cli tool qwen-image-mps. The uv recipe is very simple and shown below. The example generation, borrowed from the example used at Ivan’s repository, is a great reminder of the 1999 Fluorscence image from digitalblashsphemy.com, which drove this author’s Windows 98 SE desktop wallpaper at the time, and is likely to be the origin of the magical mushroom theme.
uv add torch --index https://download.pytorch.org/whl/nightly/rocm7.0/ uv add git+https://github.com/ivanfioravanti/qwen-image-mps.git uv add git+https://github.com/huggingface/diffusers.git
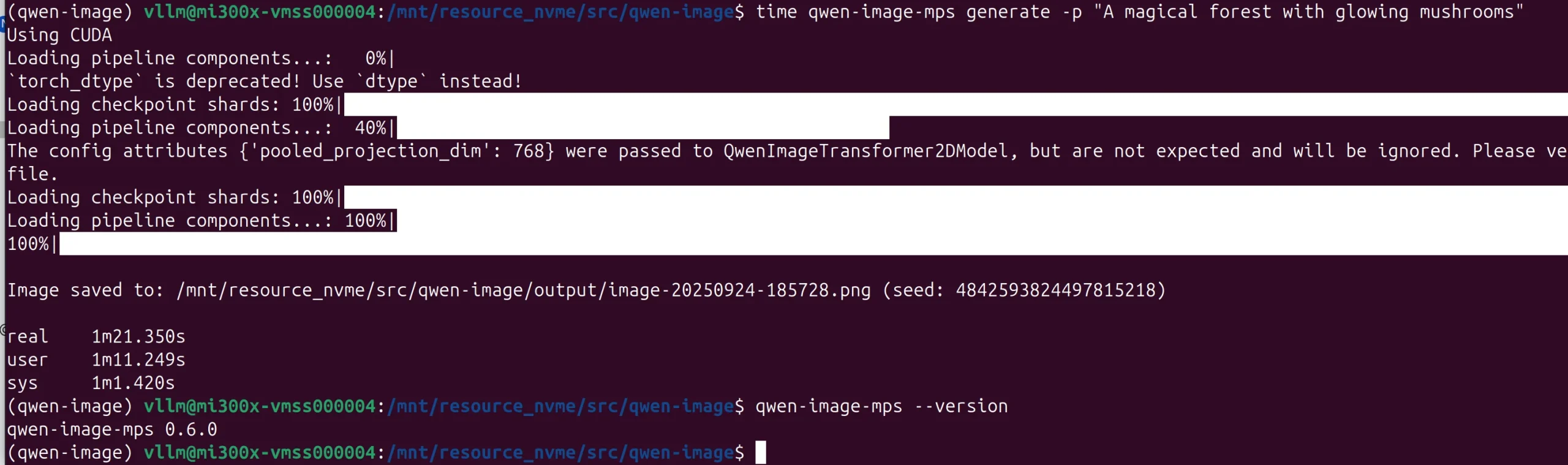
“A magical forest with glowing mushrooms”

60s of work for 1/24th of this node’s horsepower

The first Google Images mouse with no background, upscaled
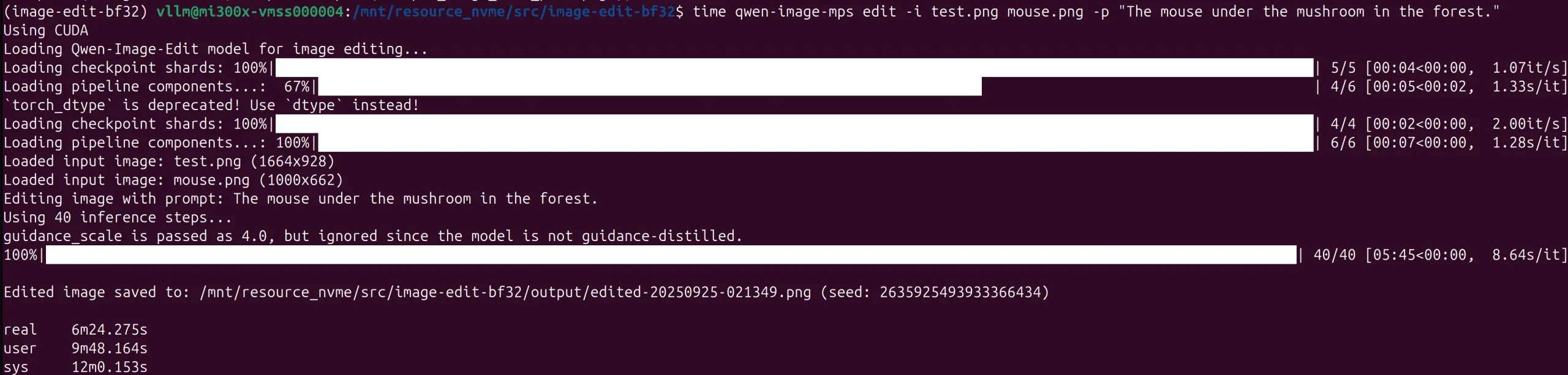
The merged edit took much longer ~10m at 1600px

Merged result from Qwen Image Edit 2509
This type of simple editing, using about 30% of one of the 8 GPUs is a great teaser for Advanced Video Generation and we hope to come back and drive a full ComfyUI workflow with Qwen-Image-Edit-2509 with additional use of the Wan2.2 Models to take advantage of multiple GPUs working in parallel for the various video, audio and image components. There appears to be a strong use case for creatives that might prefer to more quickly iterate through draft ideas on high powered multi-GPU nodes, generating multiple images in parallel, early in the creative process, with the goal of returning to their personal serialized and slower desktop pipeline once the scope of work has been sufficiently reduced.
Granite 4
IBM’s new Granite 4 models dropped on October 2nd. Arguably the most relevant new model for large and small enterprise. Granite 4 brings IBM reputation, a North American brand message, and commercial certification together with a modern, scalable and performant model. The model itself is a mamba-transformer hybrid; it has properties of traditional transformer models, which are very accurate, as well as mamba model properties which enable large contexts and require less memory. These two types of model layers (mamba and transformer) are arranged in ratio of 9:1 to maintain high performance while balancing accuracy. You can read all about it on IBM’s site. The smaller versions are designed to run on low cost GPUs, mobile devices and embedded systems, and I have read that larger versions will be released. Today, the largest is granite-4.0-h-small at 32 billion parameters, with 9 billion active. A write-up at storagereview.com shows visually how only 72 GB of memory is required vs. other models performing at the same level, and we included their diagram below. The application for this node, would be to see where the ceiling on concurrency lies. One strategy for deployment, even before inference tuning, if using actual bare metal, is to set the AMD Instinct MI300X partitioning into CPX/NPS4 mode, unlocking 32 completely isolated instances to run granite-4.0-h-tiny. A second options, more relevant to this Azure configuration we are using, would be to use the SPX/NPS1 configuration. This could drive 16 instances of granite-4.0-h-small, placing 8 into each numa zone sharing system resources, and then using vLLM and ROCm configuration to bind only 2 instances to each GPU sharing 192 GB of memory. Evaluating concurrency throughput vs latency with these different patterns while pushing overall throughput to a limit, would make an interesting experiment if we find the cycles. Note: For anyone using this model, with tool calling, it requires the hermes tool parser enabled in vLLM 0.11.0 or newer.
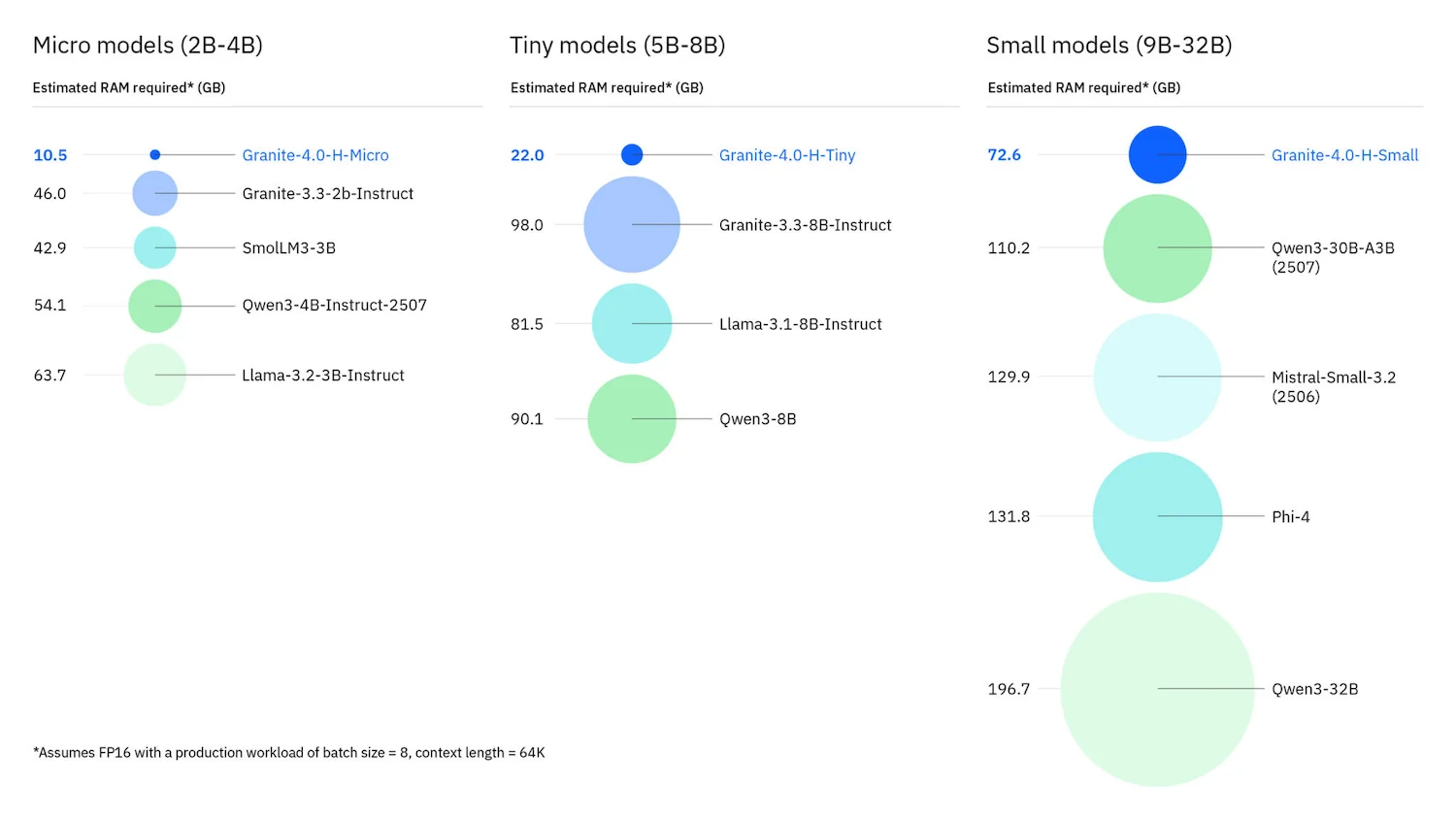
VRAM Memory Graph of Comparable Models
GLM-4.6
GLM-4.6 dropped on September 30th in Hugging Face. The ability to run very large models with full precision are what separates the 8xMI300X with 1.5 TB of HBM3 apart from other platforms. One of the big threads for GLM-4.6 is its claimed abilities for coding, when given access to tools. This is further enhanced by an extended context window at 201k tokens, which allows for tackling larger features and more complex code with each iteration. It was no surprise to us that GLM-4.6 was released the day after Claude Sonnet 4.5.
The model loaded right up using the default AMD stable vLLM build without any additional environment flags set. The Triton inference engine was select by default and initially we saw a consistent 33-40 tokens/s on our single concurrency. We turned on AITer kernel ops and hit an issue where the AITer fusedMoE operator requires that the number of experts in each decode layer of the model, is a power of 2. The full precision GLM-4.6 has 160 experts in each of its 92 decode layers, and this causes a full stop in the normal path where AITer is just turned on. The specific error message is.
Worker failed with error 'num_experts must be a power of 2, but got 160'
Early Numbers: Big-Model Sweet Spot
The quick solution, to get AITer into the mix, is to use a few environment variables to steer vLLM’s internal logic away from the AITer fusedMoE operator and towards another modular one without disabling other AITer optimizations.
VLLM_ROCM_USE_AITER=1 VLLM_ROCM_USE_AITER_MOE=0 VLLM_USE_FLASHINFER_MOE_FP16=1
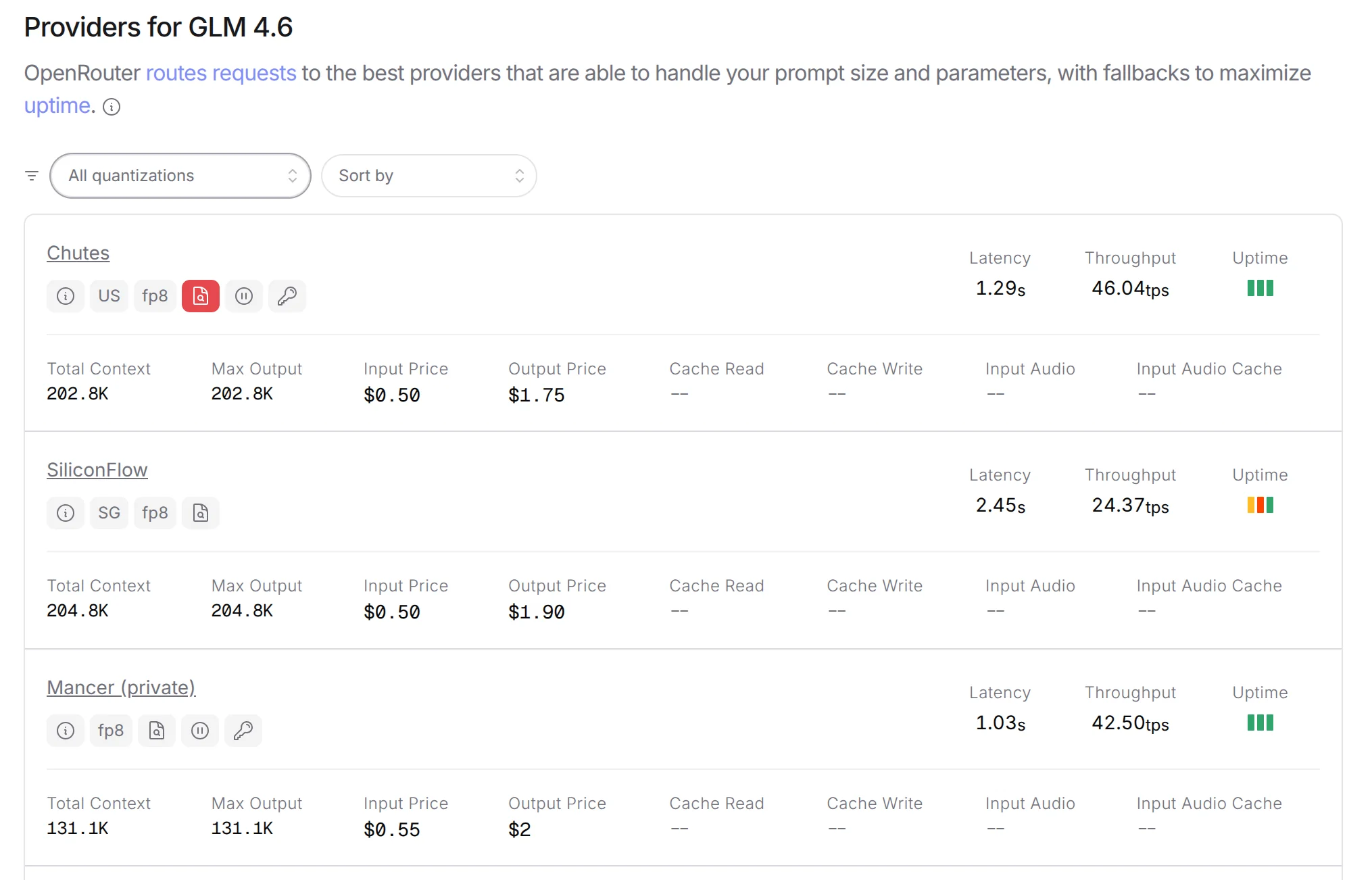
OpenRouter GLM-4.6 Provider Check
This yielded about 45 token/s which was ahead of most of the BF16 day zero offerings on openrouter.ai at the time serving higher batch sizes, so we decided this was sufficient throughput to evaluate how the model performed.
We made one more switch to the current AMD nightly build, with no changes to our environment, and ended up with a few more tokens/s and improved latency, providing a vLLM bench pattern consistently close to the one below.
============ Serving Benchmark Result ============ Successful requests: 1 Request rate configured (RPS): 10000.00 Benchmark duration (s): 20.23 Total input tokens: 8000 Total generated tokens: 1000 Request throughput (req/s): 0.05 Output token throughput (tok/s): 49.43 Peak output token throughput (tok/s): 51.00 Peak concurrent requests: 1.00 Total Token throughput (tok/s): 444.83 ---------------Time to First Token---------------- Mean TTFT (ms): 511.79 Median TTFT (ms): 511.79 P99 TTFT (ms): 511.79 -----Time per Output Token (excl. 1st token)------ Mean TPOT (ms): 19.74 Median TPOT (ms): 19.74 P99 TPOT (ms): 19.74 ---------------Inter-token Latency---------------- Mean ITL (ms): 19.74 Median ITL (ms): 19.83 P99 ITL (ms): 20.90 ==================================================
vLLM ROCm Environment Complexities
Looking at what to tune next, the myriad vLLM environment variables and serve settings need to be reviewed, and then impactful options tested under different workloads to find the optimal path for GLM-4.6. The constant momentum of changes and improvements to both vLLM and ROCm AITer stack continues to drive new optimizations weekly. Reviewing the current vLLM options in the repository is a good place to start undertanding what knobs can be turned. Reviewing the AITer release notes and vLLM release notes can also often surface new features and their associated environment flags or configuration options.
The volume of tunables makes performance evaluation incredibly nuanced. New features, attention logic, kv cache capabilities and kernel operators are constantly changing with new options available all the time. Within the AMD family, moving between CDNA and RDNA platforms requires keeping track of patterns for compatibility and for breaking changes. For example, on the AMD Instinct MI300X we have a bunch of static settings that are generally always on.
HIP_FORCE_DEV_KERNARG=1 #Puts kernel arguments directly into device memory NCCL_MIN_NCHANNELS=112 #turns on all channels in the Infinity fabric between all GPUs TORCH_BLAS_PREFER_HIPBLASLT=1 #specifies to use hipBLASLt over rocBLAS for performance HSA_OVERRIDE_CPU_AFFINITY_DEBUG=0 #keep ROCm threads aligned with their numa zone, given our dual 48-core intel architecture backend SAFETENSORS_FAST_GPU=1 #load safetensors directly to GPU memory
Environment variables for AITer, particularily transient ones for new features, are sometimes only documented in PRs and are not fully merged upstream, at least from a documentation perspective.
AITER_JIT_DIR - works with JIT_WORKSPACE_DIR to allow storing dynamically generated kernels for AITer ops in a separate cache outside the build environment path, avoiding delays required to build them each time vLLM starts up.
AITER_ONLINE_TUNE=1 - allows padding to find find a compatible kernel when the tuning logic determines there is not a match
The vLLM list available in the source is the best reference for current vLLM flags and toggles, well ahead of the online documentation by almost a full minor version, and shows a modification date almost 3 months old at the time of writing.
When models are released, new novel configurations can require the selection of a specific attention backend in order to govern which logic path configuration a particular model will follow. Recently a number of older v0 backends were disabled by default, however there is still quite a bit of choice for just the AMD ROCm stack on v1 in vLLM 0.11.0. As you iterate through models and configuration, the high level attention backend is always emitted on the console at startup once the decision tree logic begins to execute. It is a good indicator when you are familar with an optimal path.
Using Triton MLA backend on V1 engine. Using AITER MLA backend on V1 engine. Using Aiter Unified Attention backend on V1 engine. Using Rocm Attention backend on V1 engine. Using Flash Attention backend on V1 engine. Using Triton Attention backend on V1 engine. Using Aiter Flash Attention backend on V1 engine.
Deepwiki does a great job of visualizing the decision tree logic. A good starting point on AMD is VLLM_ROCM_USE_AITER=1. Both AMD and vLLM are working on more automatic optimization for v0.12.0 and even on AITer specifically if this PR is accepted in a future version.
All of these additional variations present a small challenge in running a model sweep that might aim to test each knob looking for the fastest path for a given scenario or to evaluate a specific improvement in the stack. Generating performance metrics with tools like MAD work, however there are gaps in the selection of environment setup, container launching, command line parameters, and use therefore requires quite a bit of ‘wrapper’ effort to get the job done. Even with recipes for tuning batch sizes, context, sequence and concurrency, etc. there is still a lot of work involved in discovery of the optimal configuration for any model.
Vibe Coding with GLM-4.6
We decided that solving this issue, or making our model sweep more efficient, was also a good challenge for GLM-4.6 in full precision. For the time being, we parked our ambitious model sweep goal, and focused on giving GLM-4.6 a fair shake at coding, whilst also improving our tooling for any future benchmarking activities. This is where personal interest sidelined our initial goals. We wired up Continue.dev into Visual Studio Code for this task. At full precision, the GLM-4.6 model requires all 8 GPUs to be in operation for any reasonable KV cache.
We wired up some MCP connectors (playwright and Google CSP tuned to our documentation, skipped Serena for now) and started down the path of creating a vLLM benchmark orchestration engine, complete with results collation and generation of standard graphical patterns using pandas and seaborn. It was fun and impressive. It just goes until the work is done, and tested, with each iteration. GLM-4.6 stumbled periodically with one of the Continue.dev tools, but we managed to work around that with a custom rule. In order to both test our orchestration of LLM benchmarking and test live inference on GLM-4.6 for development, on the same machine, we ran two instances of vLLM. One with GLM-4.6 limited to use only 0.85 of the GPU memory (~1.3TB of HBM3) and a second vLLM instance with model Qwen3-0.6B with 230 GB of HBM3 where we would iterate through settings, builds, environment, etc. The experience using GLM-4.6 in Continue was nothing short of great. It felt very enlightening to have an experience very similar to Claude Sonnet 4.5, except with no data going to the cloud whatsoever, using the Cloudrift.ai node to both host the brain of our lead programmer, as well as the framework we were building and orchestrating using a separate vLLM instance.
(APIServer pid=23628) INFO 10-11 17:54:18 [loggers.py:161] Engine 000: Avg prompt throughput: 15454.4 tokens/s, Avg generation throughput: 47.3 tokens/s, Running: 1 reqs, Waiting: 0 reqs, GPU KV cache usage: 2.5%, Prefix cache hit rate: 70.6%
Continue.dev and GLM-4.6 vs Claude Sonnet 4.5
Using Continue.dev in vscode, we iterated a number of new features into our vLLM vllm orchestration and analysis engine. One of the big differences over Claude Sonnet 4.5 was the full 201k token context. In Claude, we get nervous when the ‘context pie’ indicates less than 30%, and often very quickly end up with the message ‘This session is being continued from a previous conversation that ran out of context.’ The result, is that our behavior has changed, and as an example; In Claude, after solving a bug that required the agent to make few iterations unsucessfully, we are now prematurely asking Claude to stop and update architecture documentation to capture that learned pattern before the detail is lost when the context is compacted. Furthermore, we will now often document a fix before it has been fully tested by the agent, to eliminate the risk of losing that pattern, if the context expires resolving any fallout from final testing. From a behavior perspective, the opposite was the case with Continue.dev and GLM-4.6. In Continue, when the ‘context battery’ is near 66% full, it can still take considerable time and use, before the warning about context running out is presented; And that still leaves us with plenty of context for documentation updates. The result is that we are more comfortable taking on larger feature iterations and have had better capture of tricky patterns that in turn makes any future context more effective. The best analogy I can come up with, is that Continue.dev with GLM-4.6 feels like a car, that when showing 1 km of gas left in the tank, could actually drive another 20km. Claude on the other hand, can feel like a car indicating 40km of gas left in the tank, but then actually runs out unexpectedly after 20km. Disclaimer: It is early days, we are a Claude Max subscriber, and do not have the deep experience to qualify the development output of either agent; We have already learned a few more tricks that might give Claude the upper hand.
Simplified Chinese Leak
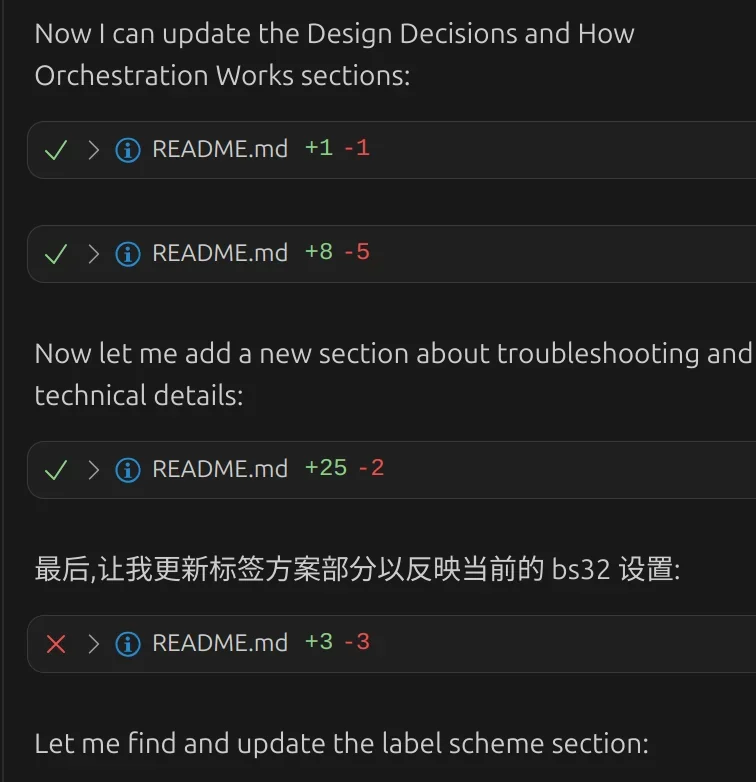
Simplified Chinese in our GLM-4.6 output
One of our goals was to process enough tokens to observe non-english characters coming out of GLM-4.6, after reading that this was fairly common. It only took about an hour of use improving our ansible playbook for the pending vLLM matrix bench run before we hit our first non-english language leak.
If you translate the simplified Chinese characters, it reads “Finally, let me update the label scheme section and reflect the current bs32 settings.” It was just a blip, and we trucked on. This could probably be solved with a negative rule easily, similar to when using generative prompts with Qwen-Image-Edit-2509. I would say the inconvenience factor was in the realm of Claude Sonnet 4.5 asking to /renew (a function that doesn’t exist), requiring just a context replay to pass by. The important fact is that this output was not garbage, but merely behaving in a multi-lingual manner. “Sleep talking” in its native tongue. I kind of like the idea that you might think another language looks improperly decoded characters, but with the right cipher, appears to be accurate and precise. Fine tune away, but I prefer “always right, but sometimes in another language”, over any strategy to eliminate the problem while degrading either accuracy or precision. In fact, downstream from an effective planning agent, it would not have any impact. It possibly goes the other way, if unstructured data gathering also needs to be translated [on the fly]. Enter the new language CrewAI.
GLM 4.6 Benchmarking
As much as we wanted to just continue using GLM-4.6, we could not benchmark it specifically, and use it for development at the same time. We switched over to Claude Sonnet 4.5, to handle feature refinements while we ran the first series of benchmarks. The new orchestration system can produce a variety of different types of graphics. It processes the vLLM bench serve JSON labels which include details on each build, environment and command line parameters in order to enable automation of the results presentation for a variety of scenarios without having to manually input or update and titles, captions, legends, axis labels, themes, etc.
In the bench runs so far, there is already a lot of variability; Below are some early image examples. The performant paths are farther down our matrix, so we have lots of gains to make. It is taking far longer than anticipated, as some of the variants create load times loading tensors, generating graphs and building kernel operators that are 5 minutes long before the benchmark starts which can range from a few seconds, to up to five minutes. We are going to restructure our test plan to skip right to performant configurations, rather than be comprehensive, as our time on this system is limited. We intend to share some great stepwise recipes for vLLM on large models like GLM-4.6, Ring 0.1T and others, probably each with a model specific post. The partial iteration below indicates that the third facet is getting patterns before the first two, as it shows a few more results. At least one path in the batch of 16 has found some gains. Others failed or were removed as invalid (missing bars) which can happen on first pass if a JIT build takes place. This is identified by large deviations in the P99 latency, and automatically excluded from the data load. The actual results are a WIP, so this is just a sample.
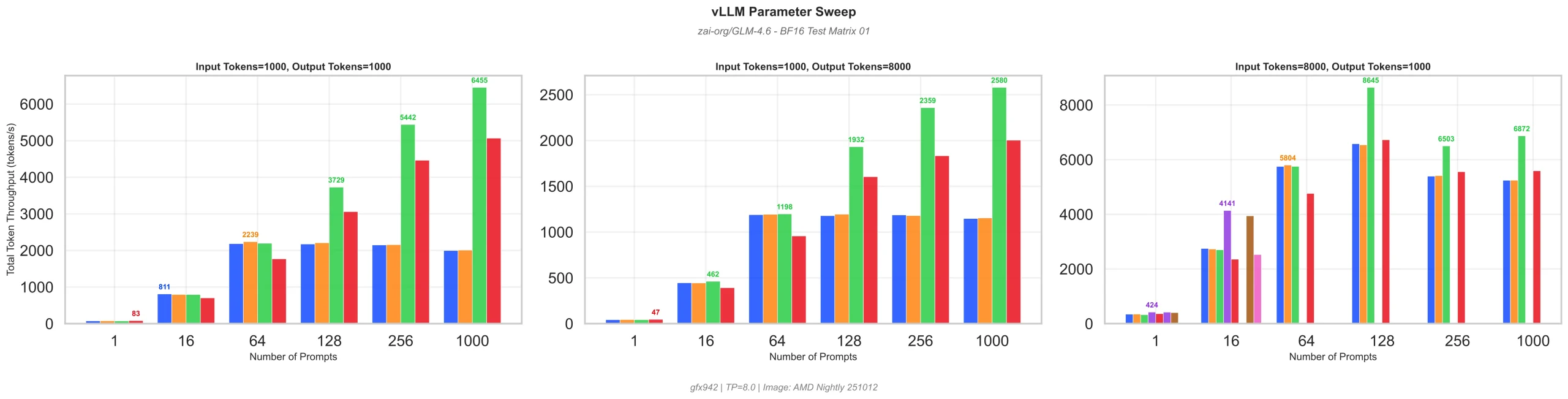
Faceted Dodges of different workloads from our new vLLM Orchestration Engine on various ROCm scenarios (labels removed)
GLM 4.6-FP8 and GLM-4.6-Air
The GLM-4.6-Air series, when released, is expected to have an experts per layer that is a power of 2, and works with the AITer fusedMoE operator. It will allow us to benchmark that kernel against the ones we are using for GLM-4.6 and expect significant gains on throughput. The FP8 version also provides opportunities to increase throughput or decrease latency for the same context length, depending on the approach to parallelism across multiple GPUs. Given that the accuracy on FP8 is considered to be negligible vs the full precision BF16 we have been running up until now, we fully expect FP8 to be fast and furious. In theory we expect to double the batch size while keeping other parameters unchanged.
What a Remarkable 4 Weeks for Open Source AI
https://github.com/pytorch/pytorch/releases/tag/v2.9.0
https://github.com/ROCm/ROCm/releases/tag/rocm-7.0.2
https://github.com/vllm-project/vllm/releases/tag/v0.11.0
https://huggingface.co/zai-org/GLM-4.6
https://huggingface.co/inclusionAI/Ring-1T
https://huggingface.co/Qwen/Qwen-Image-Edit-2509
https://huggingface.co/Qwen/Qwen3-Next-80B-A3B-Instruct
https://huggingface.co/ibm-granite/granite-4.0-h-small
https://huggingface.co/Wan-AI/Wan2.2-Animate-14B
Ready to Build on This?
Building for the future without creating technical debt is a powerful paradigm. We enjoy unfurling the details, and coming up with strategies that avoid building from source, and preserve a forward thinking upgrade and security management strategy. If you are looking for help along the lines of some of the things discussed in this post, contact us to see how we can help. If you’re in the Toronto area, we can grab a coffee (or a beer) and talk shop.
Helpful References
Most links are embedded in the article, however these were additionally flagged in our research as good sources of information.
https://blog.vllm.ai/2025/08/20/torch-compile.html
https://rocm.blogs.amd.com/artificial-intelligence/vllm/README.html
https://rocm.blogs.amd.com/artificial-intelligence/pytorch-tunableop/README.html
https://rocm.blogs.amd.com/artificial-intelligence/vllm-optimize/README.html
https://rocm.blogs.amd.com/software-tools-optimization/vllm-0.9.x-rocm/README.html
https://rocm.blogs.amd.com/artificial-intelligence/fp4-mixed-precision/README.html
https://rocm.blogs.amd.com/artificial-intelligence/audio-driven-videogen/README.html
https://rocm.blogs.amd.com/artificial-intelligence/video-generation-models/README.html
https://rocm.docs.amd.com/projects/composable_kernel/en/latest/conceptual/Composable-Kernel-structure.html
https://deepwiki.com/vllm-project/vllm
https://docs.vllm.ai/en/latest/design/hybrid_kv_cache_manager.html
https://github.com/vllm-project/vllm/blob/main/vllm/platforms/rocm.py