Run GPT‑OSS‑120B on Strix Halo (Ubuntu 25.10) — 40-45 tok/s, no containers
OS: Ubuntu 25.10 (kernel 6.17 series)
Drivers: AMDGPU 30.20 + ROCm 7.1 (via APT, using repo.radeon.com)
Python: 3.13 managed by uv (APT repos), lockfile‑reproducible venv
Hardware: Bosgame M5 128 GB
Serving: Lemonade + llama.cpp (TheRocK)
gpt-oss-120b-GGUF perf: ~40 tokens/s
On current Strix Halo boxes (e.g., Ryzen AI MAX+), Ubuntu 25.10 “just works”: the stock kernel recognizes AMDXDNA and AMD’s Instinct 30.20 (amdgpu) + ROCm 7 packages install entirely via APT—no compiling, git pulls or tarballs. With Lemonade on Strix Halo, you can serve gpt‑oss‑120b (GGUF) on the iGPU through llama.cpp‑ROCm and expose an OpenAI‑compatible API. The setup is fully reproducible using uv, can be run headless, and takes very little time to get going. Updated on 11/03/25 to reflect Ubuntu 25.10, ROCm 7.1 and TheRock 7.10 release.
All steps below use Ubuntu/Debian tooling (apt, bash, vi) and prioritize forward‑compatibility, and easy rollback.
Dual Boot Setup
- Cloned the original SSD to a 2nd M.2 NVMe drive using gparted from the Ubuntu USB live installer.
- Resized C: and Moved Recovery to create free space at the end of the disk, preserving Win11 recovery actions.
- In the system BIOS: enable SR-IOV/IOMMU, leave Secure Boot ON (allows us to enroll MOK for DKMS) – DEL to Ener BIOS, F7 for Boot Selection on the Bosgame M5
root@ai2:~# uname -a Linux ai2 6.17.0-5-generic #5-Ubuntu SMP PREEMPT_DYNAMIC Mon Sep 22 10:00:33 UTC 2025 x86_64 GNU/Linux
imac@ai2:~$ journalctl -k | grep -i amdxdna Sep 03 11:39:43 ai2 kernel: amdxdna 0000:c6:00.1: enabling device (0000 -> 0002) Sep 03 11:39:44 ai2 kernel: [drm] Initialized amdxdna_accel_driver 0.0.0 for 0000:c6:00.1 on minor 0
The 2TB NVMe drive that came with this box is shown below. It was modified using gparted on the Ubuntu USB live boot prior to installation. New Linux users with a shipped device that includes Windows 11, may opt to to create a single new p5 partition for the Ubuntu 25.10 instance and skip the additional partitioning exercise. Creating a second new partition (p6) is not required for running Lemonade on Strix Halo, and has no impact on any steps described in this post. The Ubuntu installer will allocate free space to a selected new partition on the device during the installation process, and can “Install Ubuntu alongside Windows” handling all resizing on its own.
Disk /dev/nvme0n1: 1.86 TiB, 2048408248320 bytes, 4000797360 sectors Disk model: KINGSTON OM8PGP42048N-A0 Units: sectors of 1 * 512 = 512 bytes Sector size (logical/physical): 512 bytes / 512 bytes I/O size (minimum/optimal): 512 bytes / 512 bytes Disklabel type: gpt Disk identifier: 79708580-B666-424E-8D0D-C785190FA328 Device Start End Sectors Size Type /dev/nvme0n1p1 2048 206847 204800 100M EFI System /dev/nvme0n1p2 206848 239615 32768 16M Microsoft reserved /dev/nvme0n1p3 239616 616009727 615770112 293.6G Microsoft basic data /dev/nvme0n1p4 616009728 618057727 2048000 1000M Windows recovery environm /dev/nvme0n1p5 618057728 1071108095 453050368 216G Linux filesystem /dev/nvme0n1p6 1071108096 4000794623 2929686528 1.4T Linux filesystem
The Strix Halo crypto performance is excellent. I wrap nvme0n1p6 with LUKS encryption, and the system hardly blinks, hitting over 13 GB/s in hardware-supported decode. The second M.2 slot creates an opportunity for RAID 1+0 reconfiguration for added performance and redundancy, should those become considerations for a longer term deployment plan.

Dual PCIe 4.0 M.2
imac@ai2:~$ lsblk ... nvme0n1 259:0 0 1.9T 0 disk ├─nvme0n1p1 259:1 0 100M 0 part /boot/efi ├─nvme0n1p2 259:2 0 16M 0 part ├─nvme0n1p3 259:3 0 293.6G 0 part ├─nvme0n1p4 259:4 0 1000M 0 part ├─nvme0n1p5 259:5 0 216G 0 part / └─nvme0n1p6 259:6 0 1.4T 0 part └─lvm_crypt 252:0 0 1.4T 0 crypt └─nvme1-models 252:1 0 500G 0 lvm /mnt/models imac@ai2:~$ cryptsetup benchmark ... aes-xts 256b 13151.8 MiB/s 13010.5 MiB/s ...
Add AMDGPU & ROCm APT repos
(Updated: 10/22/25) Using the amdgpu-install package is the recommended way to go if you are not an apt native. AMD have recently updated their documentation and instructions found there should just work now. On newer Ubuntu 25.04 and 25.10 systems, if you are going to use the installer, then you should ignore prompts by apt recommending you use sudo apt modernize-sourcesas it will result in duplicate files being created on apt upgrades until AMD adopt the newer .sources format over the legacy .list format still required to support Ubuntu 22.04.
Via Install Wrapper
wget https://repo.radeon.com/amdgpu-install/7.1/ubuntu/noble/amdgpu-install_7.1.70100-1_all.deb sudo apt install ./amdgpu-install_7.1.70100-1_all.deb sudo amdgpu-install --usecase=rocm
Via Apt Directly
You can skip this section, if you used the install wrapper deb. You can also browse for newer releases here and here. NOTE: Updated 11/25 to ‘7.1‘ and ‘30.20‘ in the apt sources. For the Instinct 30.20 amdgpu drivers, Debian 13 and Ubuntu 25.x use the ‘noble’ repository. Older distributions use the ‘jammy’ repository to maintain ABI compatibility. Similarily, newer distributions, i.e. Ubuntu >25.10, Debian >13 will use+ the amdgpu component that ships with the kernel package, and so the amdgpu-dkms package can be left out entirely, though the amdgpu-dkms-firmware package may still be required to ensure you have the current Strix Halo firmware.
# Key (/etc/apt/keyrings for user managed vs. /usr/share/keyrings where packages deploy) curl -fsSL https://repo.radeon.com/rocm/rocm.gpg.key \ | sudo gpg --dearmor -o /etc/apt/keyrings/rocm.gpg # AMDGPU 30.20 echo 'Types: deb URIs: https://repo.radeon.com/amdgpu/30.20/ubuntu/ Suites: noble Components: main Signed-By: /etc/apt/keyrings/rocm.gpg' \ | sudo tee /etc/apt/sources.list.d/amdgpu.sources # ROCm 7.1 echo 'Types: deb URIs: https://repo.radeon.com/rocm/apt/7.1/ Suites: noble Components: main Signed-By: /etc/apt/keyrings/rocm.gpg' \ | sudo tee /etc/apt/sources.list.d/rocm.sources # apt preferences echo 'Package: * Pin: release o=repo.radeon.com Pin-Priority: 1001' \ | sudo tee /etc/apt/preferences.d/rocm-radeon-pin sudo apt update sudo apt install rocm rocminfo sudo apt install amdgpu-dkms
Enroll Machine Owner Key (MOK)
Secure Boot note: During DKMS install you’ll set a one‑time MOK password and enroll it on the next reboot so the kernel can load signed modules.
You can use the installer to kick off the package installation or, again you can do it yourself. If you want to use Ubuntu 25.04, rather than 25.10, simply install the amdgpu-dkms package.
Add your local user to the groups with access to the GPU hardware
Set Group Permissions and Check Status
# Group permissions for the local user to access the GPU hardware sudo usermod -a -G render,video $LOGNAME
The rocm install pulls in a bunch of math libs and runtime packages. (rocblas rocsparse rocfft rocrand miopen-hip rocm-core hip-runtime-amd rocminfo rocm-hip-libraries)
If you are coming from ROCm 6.4.4, you maybe used to the unified version numbering for the ROCm and Instinct components. This diagram from the AMD ROCm blog shows how the ROCm Toolkit and Instinct Driver (amdgpu) now evolve on separate paths. 
imac@ai2:~$ modinfo amdgpu | head -n 3 filename: /lib/modules/6.17.0-7-generic/updates/dkms/amdgpu.ko.zst version: 6.16.6 license: GPL and additional rights imac@ai2:~$ rocminfo | head -n 1 ROCk module version 6.16.6 is loaded imac@ai2:~$ apt show rocm-libs -a Package: rocm-libs Version: 7.1.0.70100-20~24.04 Priority: optional Section: devel Maintainer: ROCm Dev Support <rocm-dev.support@amd.com> Installed-Size: 13.3 kB Depends: hipblas (= 3.1.0.70100-20~24.04), hipblaslt (= 1.1.0.70100-20~24.04), hipfft (= 1.0.21.70100-20~24.04), hipsolver (= 3.1.0.70100-20~24.04), hipsparse (= 4.1.0.70100-20~24.04)> Homepage: https://github.com/RadeonOpenCompute/ROCm Download-Size: 1,050 B APT-Sources: https://repo.radeon.com/rocm/apt/7.1 noble/main amd64 Packages Description: Radeon Open Compute (ROCm) Runtime software stack
Kernel & Memory Tunables
Strix Halo’s iGPU uses RDNA3.5 and can use GTT to dynamically allocate system memory to the GPU. However, oversizing the GTT window could affect stability if loading a large model does not leave enough room for the operating system to function. This scenario will trigger OOM issues if the system lacks enough memory. If you are curious about seeing what oom-kill looks like in your kernel logs, it can be triggered with memtest_vulkan on this platform. The AMD docs additionally show a couple of environment variables that appear to control thresholds for GTT allocations to prevent this. Limited testing has shown these, when enabled and using GTT, can prevent model loading when there is memory pressure.
One notable issue (not retested since 7.0.1, may be resolved) with Lemonade’s llama.cpp+rocm stack arises when VRAM is set to 96GB in the BIOS. With this setting, loading gpt-oss-120b, or any large model, can cause you to just wait endlessly for a model to load. This appears to be some kind of issue with the mmap enabled strategy in llama.cpp misbehaving, as noted in a lemonade issue here and here. The llama-server and llama-bench under the hood of Lemonade work with –no-mmap passed directly to them, so for those trying to use Lemonade with 96GB VRAM pinned in the BIOS, there may be an option soon.
With Strix Halo, using GTT mode does not have the same restriction, and you can load any model as long as you have enough free memory. We set GTT set to 125 GiB on a headless system accessed only by ssh in multi-user mode.
You have two strategies for gpt-oss-120b or other large models with Lemonade v8.1.12. You can either a) tune the VRAM BIOS settings down and allocate GTT as you like (32768000=125GiB) or b) set your VRAM BIOS to 64 or 96 GiB and not use GTT. It is unclear to this author what benefit there is leaving GTT allocated when VRAM is set in the BIOS. For b) I set GTT to a low value of 512M, to simply avoid the default allocation of 16GB.
One note from my experience: using GTT results in slightly lower gpt-oss-120b TPS (38-41) compared to VRAM (40-45). However I have not tested this in a structured manner, or extensively as Leonard Lin. YMMV. It looks like ROCWMMA is right around the corner, which should show up in a uv –package-upgrade shortly along with using hipblaslt more effectively and enabling NPU capabilities in Linux.
a) Low VRAM, High GTT
The VRAM is set to 512MB in the BIOS and GTT is set to 125 GiB in the kernel parameters. GTT at 125 GiB is enough to load a top ten coding model (#6 on 9/14/25) like GLM-4.5-Air-GGUF with 6bit quantization in Lemonade today. If you are using the desktop of your Strix Halo, you may need to roll this back to 105GB (27648000) to reserve space for desktop applications. (Updated: 10/22/25 to address release changes with 7.0.2 – https://github.com/ROCm/ROCm/issues/5562)
sudo vi /etc/default/grub.d/amd_ttm.cfg
# /etc/default/grub.d/amd_ttm.cfg
GRUB_CMDLINE_LINUX="${GRUB_CMDLINE_LINUX:+$GRUB_CMDLINE_LINUX }transparent_hugepage=always numa_balancing=disable ttm.pages_limit=32768000 amdttm.pages_limit=32768000"
sudo update-grub
sudo reboot
imac@ai2:~$ sudo dmesg | egrep "amdgpu: .*memory"
[ 3.375071] [drm] amdgpu: 512M of VRAM memory ready
[ 3.375074] [drm] amdgpu: 128000M of GTT memory ready.
With GTT set to 125GB, we can now load models beyond the 96GB BIOS limit if using the BIOS to set the VRAM allocation for the GPU. On our optimized headless system (systemctl set-default multi-user.target), we load GLM-4.5-Air-UD-Q6_K_XL , Qwen3-235B-A22B-Instruct-2507-Q3_K_M. Qwen3 235B yields about 12 TPS today. This platform’s ability to go beyond 96GB is exciting and unique. In earlier versions, you also had to set GGML_CUDA_ENABLE_UNIFIED_MEMORY=1, described below, but no longer required.
Some common values for GTT are noted below for convienence:
131072=512 MiB 2097152=8 GiB 27648000=~105 GiB 31457280=~120 GiB 32768000=~125 GiB
When the system is shuffling memory around (dumping disk cache), you can see the movement in <tt>top</tt> cli output. GPT-OSS-120B takes about a minute to load, and GLM-4.5-AIR-UD-Q6-K-XL and Qwen3-235B-A22B-Instruct-2507-Q3_K_M take about five minutes to load. Sometimes we see the following kernel message as memory is being shuffled around.
kernel: workqueue: svm_range_restore_work [amdgpu] hogged CPU for >10000us 19 times, consider switching to WQ_UNBOUND
b) High VRAM, Low GTT
The VRAM is set to 64 or 96 GIB in the BIOS and GTT is set to 512M in the kernel module parameters. This is currently slightly more performant than Low VRAM, High GTT, but only by a few TPS for Lemonade on Strix Halo running gpt-oss-120b, so we opt to stay in GTT mode as our daily driver. (Updated: 10/22/25 to address release changes with 7.0.2 – https://github.com/ROCm/ROCm/issues/5562)
sudo vi /etc/default/grub
# /etc/default/grub.d/amd_ttm.cfg
GRUB_CMDLINE_LINUX="${GRUB_CMDLINE_LINUX:+$GRUB_CMDLINE_LINUX }transparent_hugepage=always numa_balancing=disable ttm.pages_limit=131072 amdttm.pages_limit=131072"
sudo update-grub
sudo reboot
In earlier ROCm releases, when operating with BIOS VRAM pinned to 96GB, leaving 32GB of system memory, and trying to load a large model in Lemonade (~>63GB), we see the following messages, often repeated many times and a failure to load the model.
Sep 02 17:49:11 ai2 kernel: amdgpu: SVM mapping failed, exceeds resident system memory limit
The dmesg output below shows GTT is set to 512MB via kernel parameters. (amdttm.pages_limit=131072 or ttm.pages_limit=131072 depending on whether you are using in-kernel or amdgpu-dkms to provide the amdgpu module).
imac@ai2:~$ sudo dmesg | grep "GTT memory" [ 3.333156] [drm] amdgpu: 512M of GTT memory ready.
Signal Unified Memory Allocation Logic
This setting was useful in earlier ROCm 7 releases to allow loading of large models beyond 64GB in size. A clue as to the usefulness of this flag is that it was renamed from HIP_UMA as noted here. You can see it is defined in our sample systemd unit template below.
export GGML_CUDA_ENABLE_UNIFIED_MEMORY=1
When enabled, this setting will cause invalid values to be shown in rocm-smi currently. Below is the output after a 98GB model has been loaded. There is no inference going on, as the GPU percentage reflects current load and typically goes to 99-100% when in use.
$ rocm-smi --showvbios --showmeminfo all --showuse ============================ ROCm System Management Interface ============================ ========================================= VBIOS ========================================== GPU[0] : VBIOS version: 113-STRXLGEN-001 ========================================================================================== =================================== % time GPU is busy =================================== GPU[0] : GPU use (%): 0 ========================================================================================== ================================== Memory Usage (Bytes) ================================== GPU[0] : VRAM Total Memory (B): 536870912 GPU[0] : VRAM Total Used Memory (B): 169627648 GPU[0] : VIS_VRAM Total Memory (B): 536870912 GPU[0] : VIS_VRAM Total Used Memory (B): 169627648 GPU[0] : GTT Total Memory (B): 134217728000 GPU[0] : GTT Total Used Memory (B): 14753792 ========================================================================================== ================================== End of ROCm SMI Log ===================================
Signal GEMM to use HipBlaslt
There is some design discussion on AMD’s site here. Hipblaslt is available, and an evironment variable ensures it is used all the time, however there appear to be some quirks with it. You can simply export the variable, to enable it on the command line. In the systemd unit template further down in this article, you can see it defined in the [Service] description
export ROCBLAS_USE_HIPBLASLT=1
Update PCI IDs
sudo update-pciids
Swap File
I have disabled the swap file on my system. It seems to generate SVM messages from the kernel, usually during model load when swap is enabled.
kernel: amdgpu: SVM mapping failed, exceeds resident system memory limit
Disabling swap is achieved by simply commenting the swapfile load out of /etc/fstab, as shown in the last line below
imac@ai2:~$ cat /etc/fstab # /etc/fstab: static file system information. # # Use 'blkid' to print the universally unique identifier for a # device; this may be used with UUID= as a more robust way to name devices # that works even if disks are added and removed. See fstab(5). # # <file system> <mount point> <type> <options> <dump> <pass> # / was on /dev/nvme0n1p5 during curtin installation /dev/disk/by-uuid/cea76f55-f802-4ef3-a1cd-ebda84150293 / ext4 defaults 0 1 # /boot/efi was on /dev/nvme0n1p1 during curtin installation /dev/disk/by-uuid/7E3F-BB4F /boot/efi vfat defaults 0 1 #/swap.img none swap sw 0 0
llamacpp-rocm
The Lemonade team maintain their own build of llamacpp and ROCm libraries. When Lemonade runs with debug enabled, you can see the LD_LIBRARY_PATH emitted indicating the location within the python environment. This build tracks against TheRock providing updated ROCm support for the Strix Halo.
LD_LIBRARY_PATH=/path/to/ROCm/libraries # Lemonade sets to .venv/bin/rocm/llama_server
The first time you load Lemonade, you will see this custom build downloaded and added to your environment as shown here for v8.1.8. It does not change if you go up and down Lemonade versions, so be careful to wipe your python environment if you are rolling back Lemonade versions for test scenarios.
Sep 4 15:52:55 ai2 lemonade-server-dev[4168]: INFO: Downloading llama.cpp server from https://github.com/lemonade-sdk/llamacpp-rocm/releases/download/b1021/llama-b1021-ubuntu-rocm-gfx1151-x64.zip Sep 4 15:53:03 ai2 lemonade-server-dev[4168]: INFO: Extracting llama-b1021-ubuntu-rocm-gfx1151-x64.zip to /home/imac/src/lemonade/.venv/bin/rocm/llama_server
Now on v8.1.10 we see the following after a uv upgrade
Sep 13 19:48:29 ai2 lemonade-server-dev[4430]: INFO: Downloading llama.cpp server from https://github.com/lemonade-sdk/llamacpp-rocm/releases/download/b1057/llama-b1057-ubuntu-rocm-gfx1151-x64.zip Sep 13 19:48:38 ai2 lemonade-server-dev[4430]: INFO: Extracting llama-b1057-ubuntu-rocm-gfx1151-x64.zip to /home/imac/src/lemonade/.venv/bin/rocm/llama_server
Setup Python venv with uv
I prefer uv over pyenv/poetry and use a packaged version from debian.griffo.io. (10/20/25 Update – Moved to the ROCm7 nightlies for PyTorch)
# Key curl -fsSL https://debian.griffo.io/EA0F721D231FDD3A0A17B9AC7808B4DD62C41256.asc \ | sudo gpg --dearmor -o /etc/apt/keyrings/debian.griffo.io.gpg # Repo Source echo 'Types: deb URIs: https://debian.griffo.io/apt Suites: trixie Components: main Signed-By: /etc/apt/keyrings/debian.griffo.io.gpg' \ | sudo tee /etc/apt/sources.list.d/debian.griffo.io.sources apt update apt install uv
Head to wherever you want to store your lemonade project. (Updated 10/20/25 from rocm6.4 wheels to rocm7.0)
cd ~/src/lemonade #replace with your own project location uv init --python 3.13 uv add --index rocm7_nightly=https://download.pytorch.org/whl/nightly/rocm7.0/ --index-strategy unsafe-best-match --prerelease allow "torch==2.10.0.dev20251102+rocm7.0" "torchvision==0.25.0.dev20251105+rocm7.0" "torchaudio==2.10.0.dev20251105+rocm7.0" uv add --index https://pypi.org/simple lemonade-sdk[dev]
Lemonade on Strix Halo does not require pyTorch for GGUF+ROCm, but it is useful for other LLM related tools. Pinning the ROCm wheel extras index in your pyproject.toml helps resolve some dependency extras cleanly when you pull lemonade-sdk. This also avoids installing about 1GB of extra nvidia tools and libraries that will never be used with an AMD GPU. (Updated: 11/03/25 Switch to using TheRock wheels)
Run Lemonade in the Background (screen)
Running in screen allows you to start Lemonade and leave it running in the background. You can then close your terminal window. I picked a reasonable context size, which is configurable. I also set the host so that Lemonade listens on all interfaces, not just localhost. This system is on a private network. Do not port forward or put this system on a public IP in this configuration, please.
cd ~/src/lemonade screen -S lemony # inside screen: source .venv/bin/activate lemonade-server-dev run gpt-oss-120b-GGUF \ --ctx-size 8192 \ --llamacpp rocm \ --host 0.0.0.0 \ --log-level debug |& tee -a ~/src/lemonade/lemonade-server.log
Detach from screen with CTRL-a d. Reattach with screen -r lemony. Access: http://STRIX_HALO_LAN_IP_ADDRESS:8000 from a browser on any device on the same network. Debug log level will output TPS and other useful information, but can be removed when not needed.
Lock it down
Secure the interfaces once you have it working. In this case, only two ports are required. SSH port 22 is for administration. HTTP port 8000 is for web access to the model manager and API.
sudo ufw allow 22/tcp sudo ufw allow 8000/tcp sudo ufw enable
Screen is used here, but a systemd wrapper may be better for long-term use. This would be as a service to provide an API to something like Open WebUI. When this Strix Halo is not tied up with other workloads, I have a separate Debian trixie instance that serves up Open WebUI to provide memory (look at your old chats) and advanced features for other local network users. It is a mature tool and great for engaging with private data. This is an alternative to enterprise AI chat tool subscriptions. It’s a clear candidate for enhancing household and small business productivity.
Run Lemonade at Startup (systemd)
If you are dedicating your Strix Halo to serving Lemonade, moving the service into systemd makes sense. Using your project folder and an unprivledged user, this can be accomplished with the systemd configuration below. In my case, the project location path is /home/imac/src/lemonade. Update /home/%i/src/lemonade in the unit file below to match your project location. Some of the configurable environment options are explained here.
# /etc/systemd/system/lemonade@.service [Unit] # Running as an instance with the same name as the local user Description=Lemonade Server (ROCm) for %i Wants=network-online.target After=network-online.target systemd-resolved.service # If models in LVM, or a path that might not be ready #RequiresMountsFor=/mnt/models [Service] Type=simple User=%i # Replace with your project location WorkingDirectory=/home/%i/src/lemonade # Tunable environment variables Environment=LEMONADE_LLAMACPP=rocm #Environment=LEMONADE_LLAMACPP=vulkan Environment=LEMONADE_CTX_SIZE=65536 Environment=LEMONADE_HOST=0.0.0.0 Environment=LEMONADE_PORT=8000 #Environment=LEMONADE_LOG_LEVEL=debug Environment=ROCBLAS_USE_HIPBLASLT=1 Environment=GGML_CUDA_ENABLE_UNIFIED_MEMORY=1 #If you store your models in another location, you can override the default huggingface home path #Environment=HF_HOME=/mnt/models/huggingface # You can chose to load a model at startup, or wait to load a model using the web interface #ExecStart=/home/%i/src/lemonade/.venv/bin/lemonade-server-dev run gpt-oss-120b-GGUF ExecStart=/home/%i/src/lemonade/.venv/bin/lemonade-server-dev serve Restart=always RestartSec=3 [Install] WantedBy=multi-user.target
Once the file is loaded, you can add it to your systemd configuration, and enable it to start automatically using the following commands, substituing imac with your own local username.
imac@ai2:~$ sudo systemctl daemon-reload imac@ai2:~$ systemctl enable --now lemonade@imac.service
To see the console output, you can now use journalctl just like any other service.
imac@ai2:~$ journalctl -u lemonade@imac.service Oct 22 13:14:23 ai2 systemd[1]: Started lemonade@imac.service - Lemonade Server (ROCm) for imac. Oct 22 13:14:24 ai2 lemonade-server-dev[4805]: INFO: Started server process [4805] Oct 22 13:14:24 ai2 lemonade-server-dev[4805]: INFO: Waiting for application startup. Oct 22 13:14:24 ai2 lemonade-server-dev[4805]: INFO: Oct 22 13:14:24 ai2 lemonade-server-dev[4805]: 🍋 Lemonade Server v8.1.12 Ready! Oct 22 13:14:24 ai2 lemonade-server-dev[4805]: 🍋 Open http://0.0.0.0:8000 in your browser for: Oct 22 13:14:24 ai2 lemonade-server-dev[4805]: 🍋 💬 chat Oct 22 13:14:24 ai2 lemonade-server-dev[4805]: 🍋 💻 model management Oct 22 13:14:24 ai2 lemonade-server-dev[4805]: 🍋 📄 docs Oct 22 13:14:27 ai2 lemonade-server-dev[4805]: INFO: Application startup complete. Oct 22 13:14:27 ai2 lemonade-server-dev[4805]: INFO: Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit) Oct 22 13:14:45 ai2 lemonade-server-dev[4805]: Starting Lemonade Server... Oct 22 13:14:45 ai2 lemonade-server-dev[4805]: INFO: 192.168.79.143:33910 - "GET / HTTP/1.1" 200 OK Oct 22 13:14:45 ai2 lemonade-server-dev[4805]: DEBUG: Total request time (streamed): 0.0313 seconds Oct 22 13:14:45 ai2 lemonade-server-dev[4805]: INFO: 192.168.79.143:33910 - "GET /static/styles.css HTTP/1.1" 200 OK Oct 22 13:14:45 ai2 lemonade-server-dev[4805]: INFO: 192.168.79.143:33914 - "GET /static/favicon.ico HTTP/1.1" 200 OK Oct 22 13:14:45 ai2 lemonade-server-dev[4805]: DEBUG: Total request time (streamed): 0.0051 seconds Oct 22 13:14:45 ai2 lemonade-server-dev[4805]: DEBUG: Total request time (streamed): 0.0064 seconds
Running with 128000M GTT (~125GB) yielded about 1GB of free memory during inference using with GLM-4.5-Air-GGUF-Q8_0 on a service optimized Ubuntu 25.04 desktop system running headless with debug logging enabled. It was under a few TPS at 128k context, but loaded.
root@ai2:~# free total used free shared buff/cache available Mem: 128649272 29146652 1064980 374200 99999544 99502620 Swap: 0 0 0
Understanding the MES Firmware
ROCm 7.1 ships the current AMD MES firmware, pull from the upstream linux-firmware repository, which is then repackaged for the Strix Halo in the Ubuntu linux distribution via the linux-firmware package, in addition to via the Instinct driver repository as part of the amdgpu-dkms-firmware package. If you have both packages installed, the more specific amdgpu-dkms-firmware package will override the linux-firmware package by default. Prior to AMD Instinct 30.20, the AMD packages contained firmware that did not work with the in-kernel MES software to avoid some GPU hang scenarios during long duration workflows. There are still a few issues as of 11/03/25, as described here, and the previous workaround to load the firmware package from the upstream Ubuntu Resolute Raccoon may be useful with future firmware issues if versions >0x80 become available ahead of the next ROCm release.
A command you can use to check your MES firmware is:
cat /sys/kernel/debug/dri/128/amdgpu_firmware_info | grep MES
You should see at least 0x80 as of 11/3/25.
$ sudo cat /sys/kernel/debug/dri/128/amdgpu_firmware_info | grep MES MES_KIQ feature version: 6, firmware version: 0x0000006f MES feature version: 1, firmware version: 0x00000080
On Questing before the updated firmware was installed, we observed this version from linux-firmware.
MES feature version: 1, firmware version: 0x0000007e
Below are some version identifiers we have seen and where they have come from.
amdgpu-dkms-firmware 30.10.2.0.30100200-2226257.24.04 (apt install amdgpu-dkms-firmware/noble via repo.radeon.com ROCm 7.0.2)
MES_KIQ feature version: 6, firmware version: 0x0000006c MES feature version: 1, firmware version: 0x00000077
linux-firmware 20250901.git993ff19b-0ubuntu1.2 (apt install linux-firmware/questing)
MES_KIQ feature version: 6, firmware version: 0x0000006c MES feature version: 1, firmware version: 0x0000007e
linux-firmware 20250317.git1d4c88ee-0ubuntu1.9 (apt install linux-firmware/plucky-updates)
MES_KIQ feature version: 6, firmware version: 0x0000006c MES feature version: 1, firmware version: 0x0000007c
amdgpu-dkms-firmware 1:6.12.12.60404-2202139.24.04 (apt install amdgpu-dkms-firmware/noble via repo.radeon.com ROCm 6.4.4 )
MES_KIQ feature version: 6, firmware version: 0x0000006c MES feature version: 1, firmware version: 0x0000006e
linux-firmware 20251009.git46a6999a-0ubuntu1 (apt install amdgpu-dkms-firmware/racoon and also amdgpu-dkms-firmware 30.20.0.0.30200000-2238411.24.04)
MES_KIQ feature version: 6, firmware version: 0x0000006f MES feature version: 1, firmware version: 0x00000080
Beware of not pinning Instinct apt repositories
Due to the version numbering change with Instinct 30.xx, if you installed ROCm/Instinct 6.4.4 from repo.radeon.com, you can actually end up in a situation where the amdgpu-dkms-firmware package is not being upgraded due to the package numbering if the policy is not set to explicitly use the version from AMD. This scenario, shown below with apt pinning only to 600 vs the 1001 used in the instructions above, can be inspected via the apt policy as shown below.
$ sudo apt policy amdgpu-dkms-firmware amdgpu-dkms-firmware: Installed: 1:6.12.12.60404-2202139.24.04 Candidate: 1:6.12.12.60404-2202139.24.04 Version table: *** 1:6.12.12.60404-2202139.24.04 100 100 /var/lib/dpkg/status 30.10.2.0.30100200-2226257.24.04 600 600 https://repo.radeon.com/amdgpu/30.10.2/ubuntu noble/main amd64 Packages
A similar situation occurs when upgrading 25.10 from versions prior to ROCm 7.1 in Ubuntu 25.10 as explained here. In this case, the rocprofiler shipped with Ubuntu 25.10 interferes with dependencies for the pinned ROCm 7.1 versions.
$sudo apt policy rocprofiler-sdk rocprofiler-sdk: Installed: 1.0.0-56~24.04 Candidate: 1.0.0-56~24.04 Version table: *** 1.0.0-56~24.04 100 100 /var/lib/dpkg/status 1.0.0-20~24.04 600 600 https://repo.radeon.com/rocm/apt/7.1 noble/main amd64 Packages
Pinning the AMD repository to preference 1001 resolves these situations if you come across one of them.
Basic Local Monitoring
Messages about VRAM and GTT allocations and ongoing SVM mapping failures
journalctl -b | egrep "amdgpu: .*memory"
Follow logs live to see errors in realtime
journalctl -f
Watch the GPU memory use
watch -n1 /opt/rocm/bin/rocm-smi --showuse
Inspect VRAM capacity
rocm-smi --showvbios --showmeminfo vram --showuse rocm-smi --showvbios --showmeminfo gtt --showuse rocm-smi --showvbios --showmeminfo all --showuse
Evergreening
apt update && apt upgrade
Check for bumps in the apt repositories here and here. Move to the stable or latest when new releases become available. Make a copy of uv.lock first for rollback.
uv lock --upgrade --index-strategy unsafe-best-match --prerelease=allow uv sync
Optionally, you can just upgrade lemonade
uv lock --upgrade-package lemonade-sdk
Also keep an eye on your torch wheel if you are using torch, and either update the index in your pyproject.toml or remove it so its dependencies can not conflict with lemonade.
[project]
name = "lemonade"
version = "0.5.0"
description = "Updated 11_3_2025 on Ubuntu 25.10 with ROCm 7.1 and The Rock 7.10"
readme = "README.md"
requires-python = ">=3.13"
dependencies = [
"lemonade-sdk[dev]>=8.2.0",
"torch==2.10.0.dev20251102+rocm7.0",
"torchaudio==2.10.0.dev20251105+rocm7.0",
"torchvision==0.25.0.dev20251105+rocm7.0",
]
[tool.uv]
index-strategy = "unsafe-best-match"
prerelease = "allow"
[[tool.uv.index]]
name = "pypi"
url = "https://pypi.org/simple"
default = true
[[tool.uv.index]]
name = "rocm7"
url = "https://download.pytorch.org/whl/nightly/rocm7.0/"
[[tool.uv.index]]
name = "rocm6"
url = "https://download.pytorch.org/whl/rocm6.4"
[[tool.uv.index]]
name = "therock"
url = "https://rocm.nightlies.amd.com/v2/gfx1151/"
[tool.uv.sources]
# Choose between ROCm 6, ROCm 7 and TheRock 7.10.0
torch = { index = "rocm7" }
torchvision = { index = "rocm7" }
torchaudio = { index = "rocm7" }
pytorch-triton-rocm = { index = "rocm7" }
Initial State 9/3/25 (At Publication)
apt managed
ii linux-image-6.14.0-29-generic 6.14.0-29.29 amd64 Signed kernel image generic ii amdgpu-dkms 1:6.14.14.30100000-2193512.24.04 all amdgpu driver in DKMS format. ii rocm 7.0.0.70000-17~24.04 amd64 Radeon Open Compute (ROCm) software stack meta package ii uv 0.8.14-1+trixie amd64 An extremely fast Python package and project manager, written in Rust.
uv managed
lemonade-sdk 8.1.10 / llamacpp-rocm b1021 torch 2.8.0+rocm6.4
Current State 11/03/25 (Evergreening)
At some point after initial publication, we upgraded from 25.04 (Plucky) to 25.10 (Questing) and removed amdgpu-dkms as a newer version of the module is provided with the kernel.
apt managed
ii linux-image-6.17.0-7-generic 6.17.0-7.7 amd64 Signed kernel image generic ii rocminfo 1.0.0.70100-20~24.04 amd64 Radeon Open Compute (ROCm) Runtime rocminfo tool ii uv 0.9.7-1+trixie amd64 An extremely fast Python package and project manager, written in Rust.
uv managed
lemonade-sdk 8.2.2 / llamacpp-rocm b1066 torch 2.7.1+rocm7.9.0rc1
Open WebUI
If you do want to spawn Open WebUI, similar steps below should work on Debian Trixie, and probably also on any Ubuntu Plucky instance.
sudo apt install pkg-config python3-dev build-essential libpq-dev uv init uv venv uv python pin 3.11 uv sync source .venv/bin/activate uv pip install setuptools wheel uv add open-webui open-webui serve
Performance
With the release of ROCm 7.0, a lot of people might be wondering what kind of performance they can expect. This article was based on Ubuntu 25.04, as it provides a convienent way to enjoy a complete desktop experience right on top of a Strix Halo device, while taking advantage of 100GB+ models. For more permanent workloads, we prefer pure Debian for a cleaner multi-user target that more closely resembles a commercial production environment without any overhead from desktop packages, and stricter policies and release cycles on the underlying operating system. Debian 13 is fully supported by AMD, and with ROCm 7.1 Ubuntu 25.10 it seems like all current Ubuntu and Debian versions will be added to the official support matrix any day now. Below we include benchmarks on both Ubuntu and Debian, as well as a comparison to a Radeon RX 7900 XTX GPU in our benchmarks, using some popular models at the time of writing.
llama-bench is included with the lemonade package, and is easily marked executable to avoid having to pull down any additional code, or build any packages from source to execute local benchmarks of various models. It can be pointed directly at the models downloaded in the Lemonade model manager from Hugging Face to avoid any file replication, which quickly adds up with the larger models.
QWEN3-30B-Coder-A3B – 48 t/s – Strix Halo – Debian 12 – ROCm 6.4 – LLAMA-ROCM b1057 (Lemonade v8.1.10)
There is almost no change on Debian 12 with Linux 6.1+ROCm 6.4 and moving to ROCm 7.0. Switching to Ubuntu Linux 6.14+ROCm 7.0 showing a 23% improvement in generation over Debian 12. We might expect similar for gains over Ubuntu 22.04 and will likely upgrade to Debian 13 at a later date.
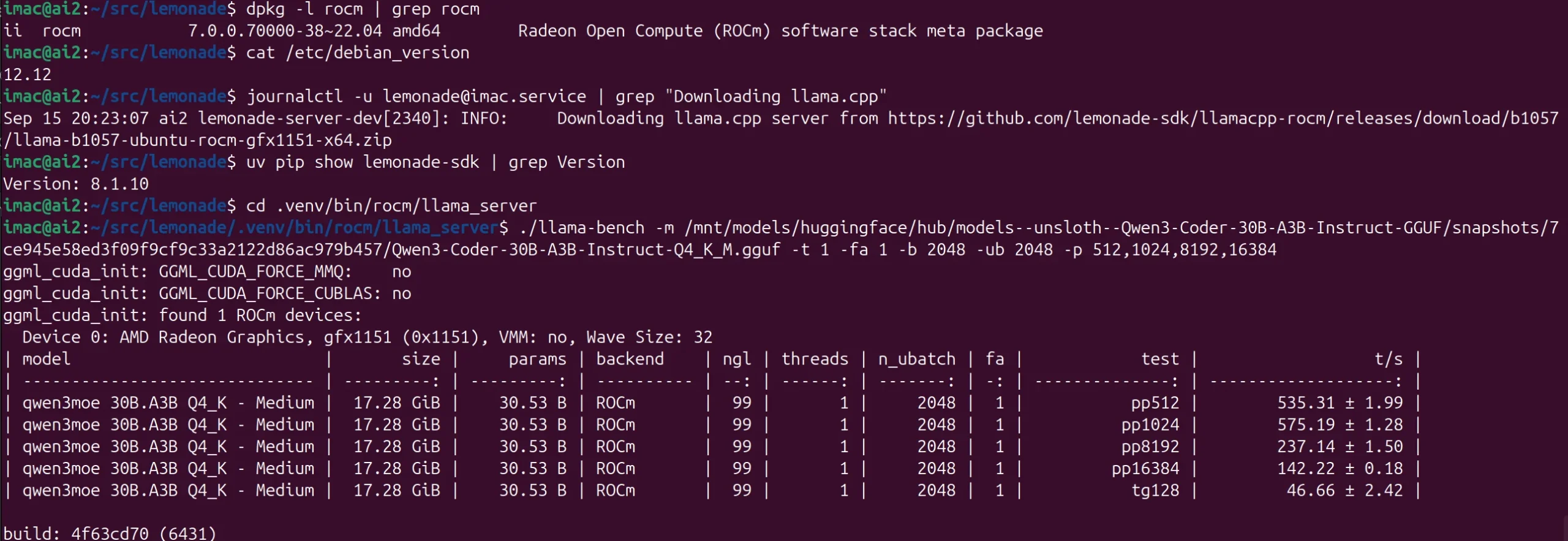

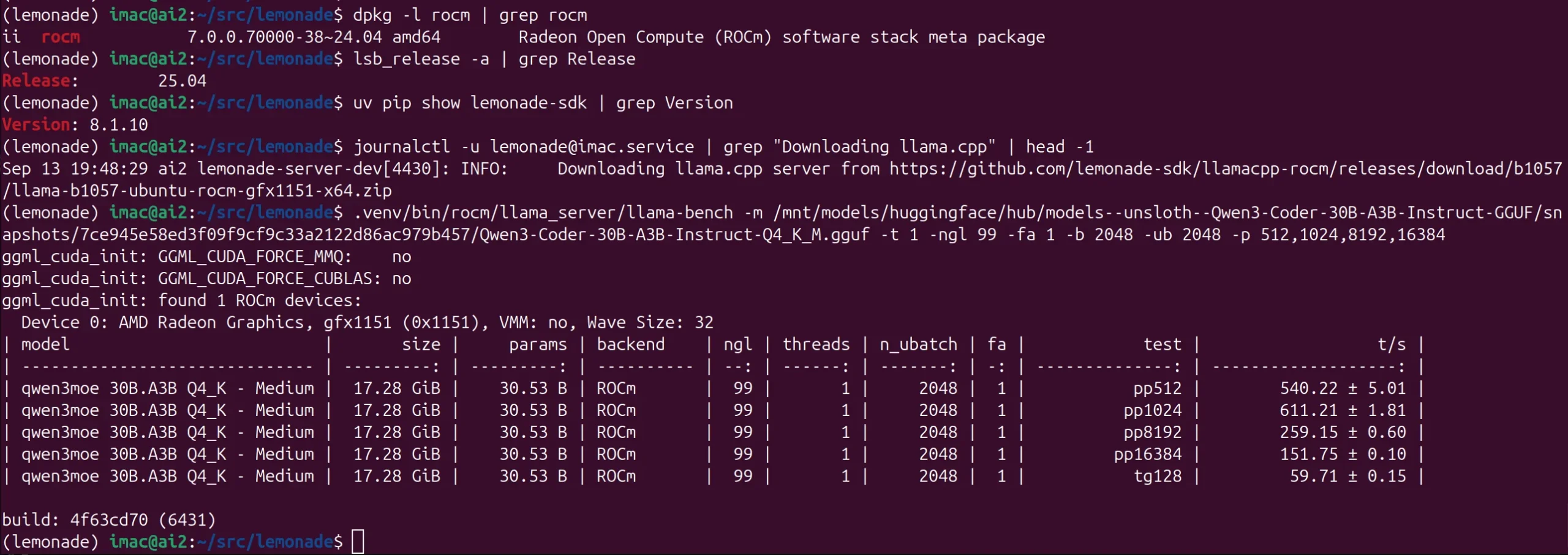
QWEN3-30B-Coder-A3B – 59 t/s – Strix Halo – Ubuntu 25.04 – ROCm 7.0 – LLAMA-ROCM b1057 (Lemonade v8.1.10)
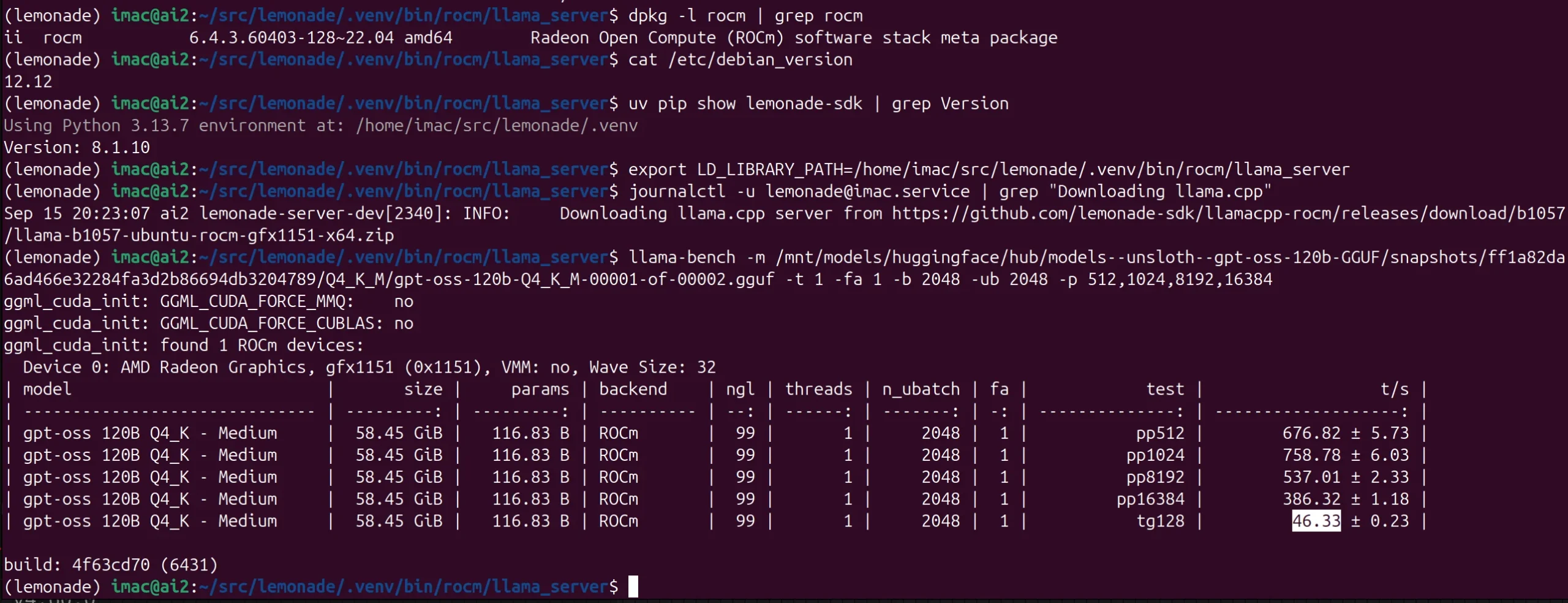
GPT-OSS-120B – 46 t/s – Strix Halo – Debian 12 – ROCm 6.4 – LLAMA-ROCM b1057 (Lemonade v8.1.10)
The difference between Debian 12 (6.1) with ROCm 6.4 and Ubuntu 25.04 (6.14) with ROCm 7.0 for this model is much smaller than with Qwen 30B.
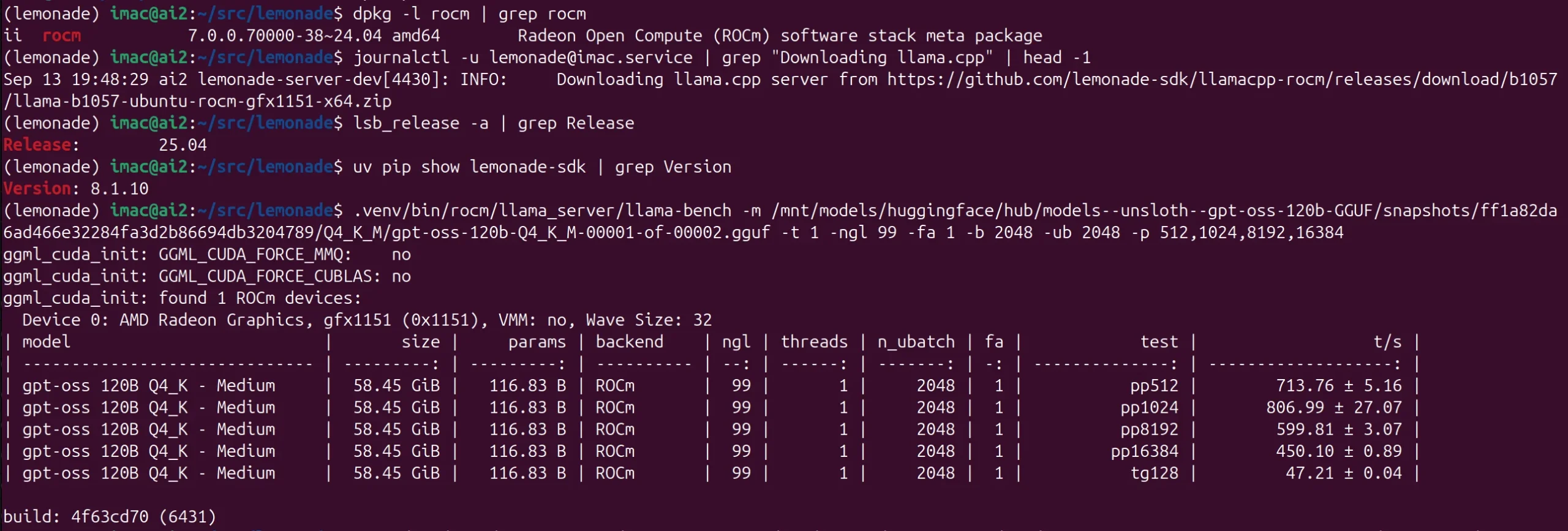
GPT-OSS-120B – 47 t/s – Strix Halo – Ubuntu 25.04 – ROCm 7.0 – LLAMA-ROCM b1057 (Lemonade v8.1.10)
QWEN3-30B-Coder-A3B – 98 t/s – RX 7900 XTX – Ubuntu 25.04 – ROCm 7.0 – LLAMA-ROCM b1057 (Lemonade v8.1.10)
The result below shows you a 24GB RDNA 3 card executing the same test. Just over twice the performance on generation, but that is about as large a model as it can handle. For 20GB models, these GPUs are available for approx $600 USD. (9/25)
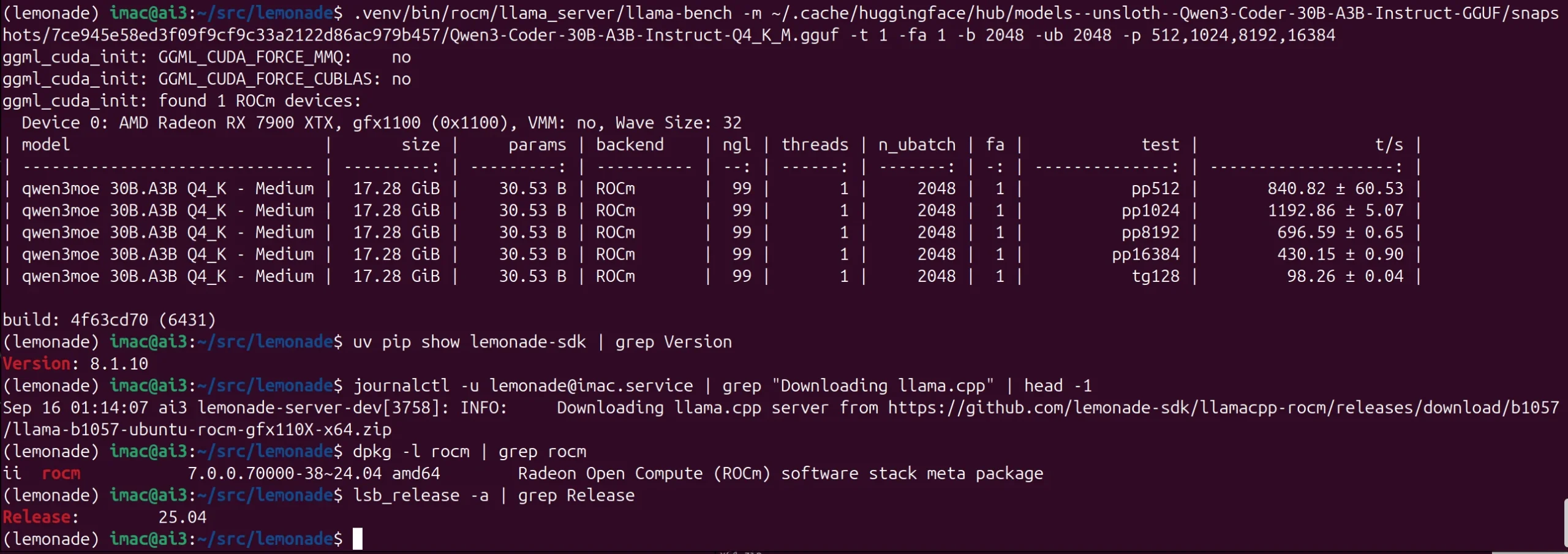
QWEN3 Big and Small – 235B-Coder-A22B Instruct 2507 – 11 t/s – Strix Halo – Debian 12 – ROCk 7.0 – LLAMA-ROCM b1057 (Lemonade v8.1.10)
Here we see how the difference in performance running some of the smallest and largest Qwen3 models. At 11 t/s if there is nothing else going on, letting Qwen 235B make optimizations and improvements to existing code, is just a fun background task.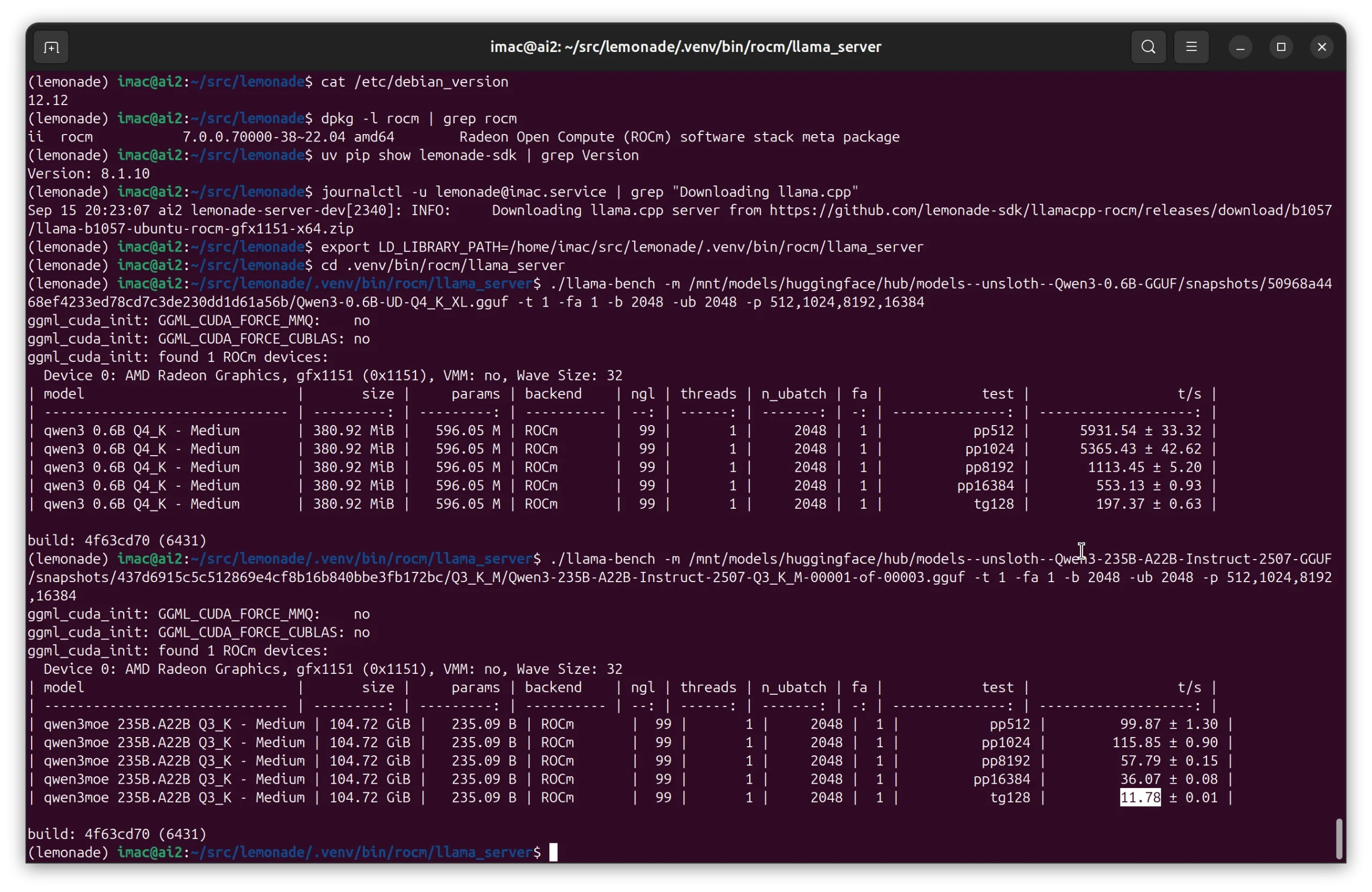
Ready to Build on This?
Building for the future without creating technical debt is a powerful paradigm. But the real business advantage comes from mapping your unique business logic into multi-agent AI workflows that solve real problems and create real scalability.
At Netstatz Ltd., this is our focus. We leverage our enterprise experience to build intelligent agent systems on stable, secure, and cost-effective edge platforms like Strix Halo. If you are a small or medium sized business looking to prototype or deploy local AI solutions, contact us to see how we can help. If you’re in the Toronto area, we can grab a coffee (or a beer) and talk shop.